Decision Making Games
Decision Making Games
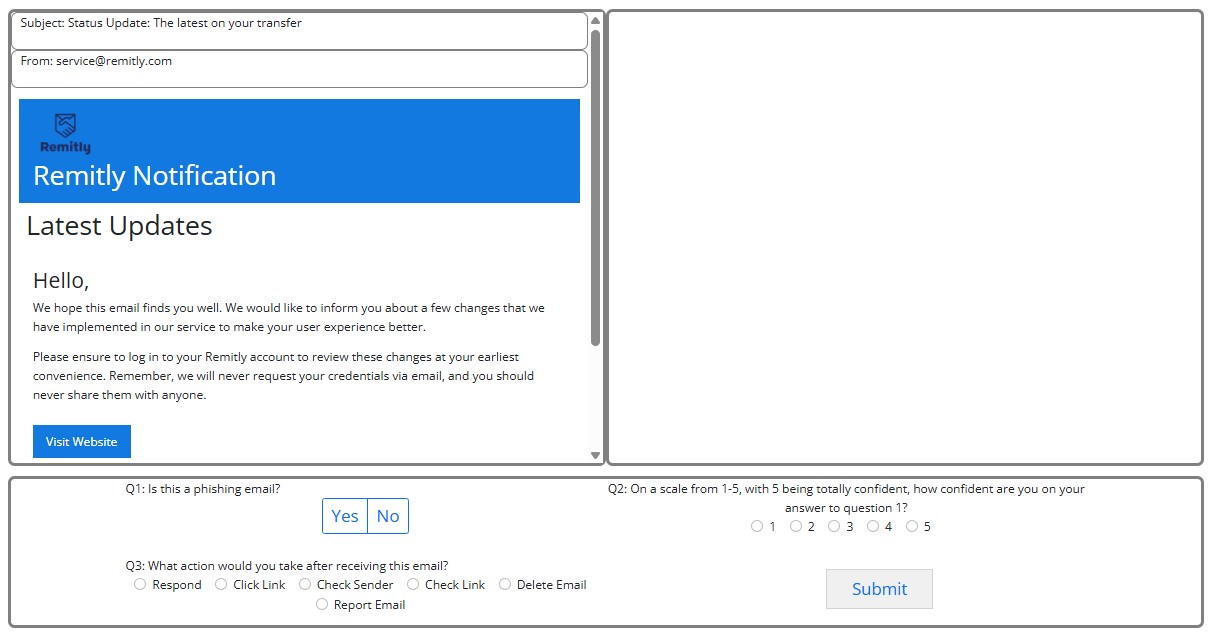
Phishing Training
This is a demo for an experiment studying how humans identify emails as being potentially dangerous phishing emails or benign ham emails. The emails in this learning platform are either generated by human cybersecurity experts or a chatbot large language model. A teacher chatbot model provides feedback to you on the accuracy of your categorization and trains you to properly identify dangerous phishing emails. Try to categorize emails as being either phishing or ham, and chat with the bot to receive feedback and learn more about phishing attempts.
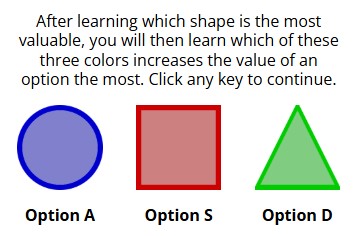
Contextual Bandit
This is a demo for an experiment studying basic human learning and decision making using abstract visual information, with different options having different shapes, colors, and patterns. With this experiment we are interested in investigating how humans learn from abstract information and how they transfer their experience from less complex to more complex decision making. Try to learn which of the shape-color-pattern options receive the most amount of points.
Disaster Analysis
This is a demo for an experiment on decision making in emergency response managers after a hurricane natural disaster. These decisions include assessment of damage and allocation of resources. Our goal is to understand the features that emergency response managers use to assess areas for their need of additional resources. Choose which of the houses you would allocate additional resources to, and categorize these houses based on their level of damage across different damage types.

Human-AI Teaming and Preferences Using Overcooked
This is a demo for an experiment on Human-AI teaming and preferences for controllability in a reproduction of the Overcooked-AI environment that uses CoGrid and Interactive Gym. Our goal is to understand how people interact with controllable AI partners in a collaborative task. Choose between three different partner types and play a round of the game with them!

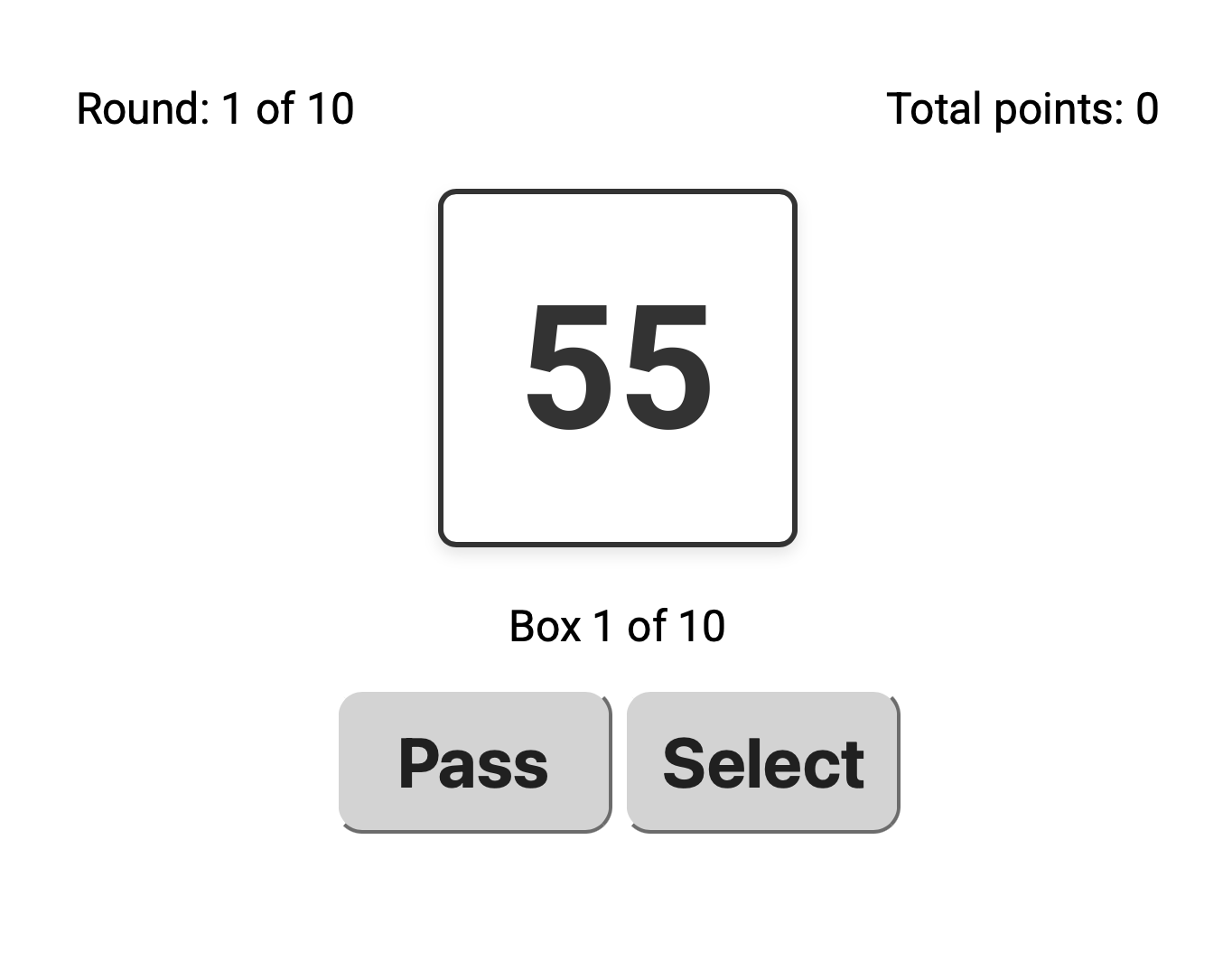
Optimal Stopping Task Demo
This is a decision making task called the optimal stopping task. You will explore a sequence of boxes and decide when to stop searching and select a box. Your goal is to select the box with the highest value in the sequence. In this demo, you can try three different experimental conditions from an experiment we conducted.
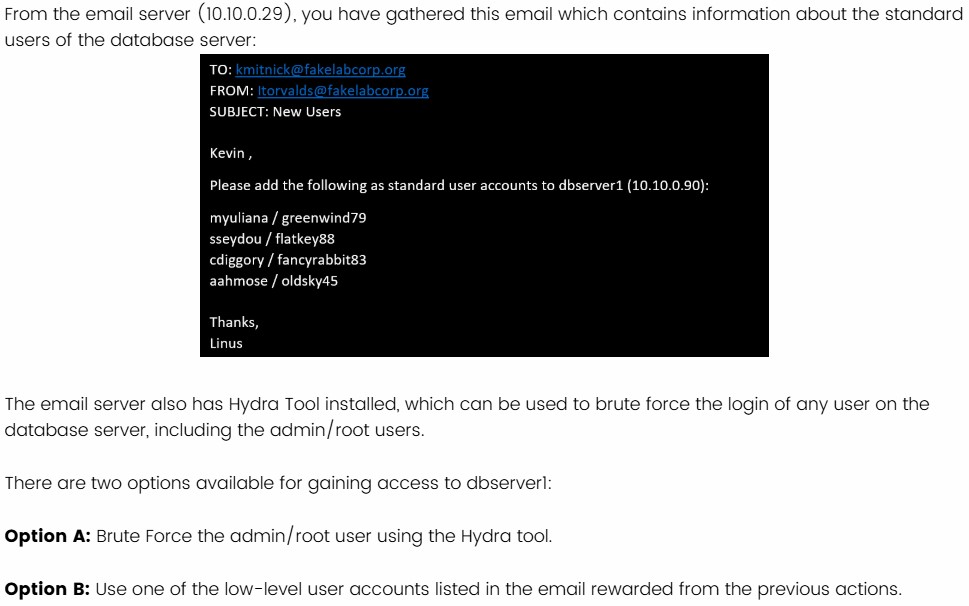
Cyber Attack Demo
This is a Cyber Attack Flow demo. Participants needs to have knowledge of cyber kill chain phases and basic understanding of cyber security concepts. Participants are provided with a defined objective at the beginning with the aim to successfully achieve that goal without being detected in the network. This attack flow is a sequential choice based task. You will be provided with feedback on your progress as you proceed.
Interactive Gridworld
This is an interactive goal-seeking task in an environment called "gridworld". To do this task, a player needs to make sequential decisions about going up, down, left or right to explore the space. There are four colored targets that give the player points. The goal is to find the target with the highest value. In addition, the player is penalized 1 point for each decision made (i.e., a movement cost) and 5 points for walking into an obstacle.
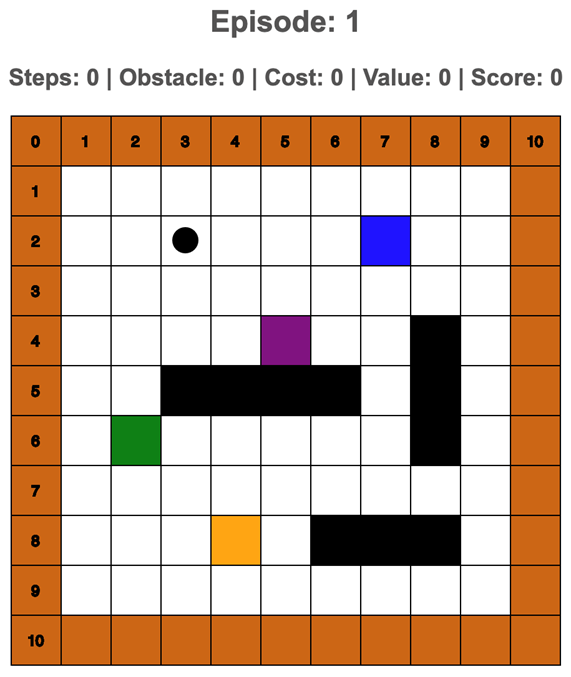
Implemented by: Ngoc Nguyen
One-Step Gridworld
The One-Step Gridworld is the same task as the goal-seeking Gridworld task. However, the difficulty in One-Step Gridworld is that at each step the decision maker is only informed of their current position, the number of steps already taken, and the cost or benefit of the step taken as illustrated in the figure below.
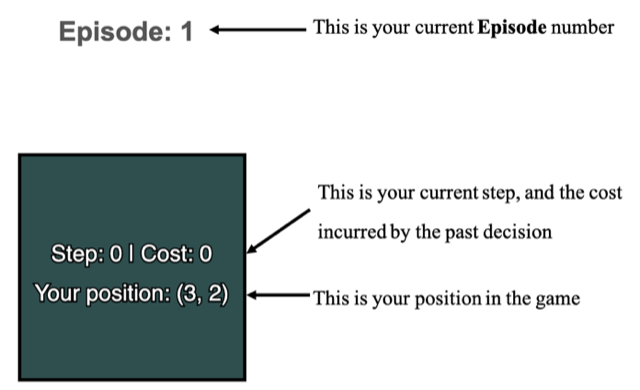
Implemented by: Ngoc Nguyen
Interactive Minimap
This is an interactive "search and rescue" task in which the player will explore the rooms in a building to find victims and rescue them. In the building there are two types of victims: the Green victims are less injured, and they will give the player 10 points, if rescued. The Yellow victims are more injured, and they will give the player 30 points, if rescued. The Yellow victims die after 4 minutes: they will disappear from the building, and the Green victims will not die during the mission.

Implemented by: Ngoc Nguyen
Interactive Defense Game
In this interactive cyber-defense task, you have been contracted to defend the computer network of a major company at one of their manufacturing plants. Attackers are trying to get access to the Operational Server to steal the plans and disrupt the production. Your goal, as a security expert, is to minimize your loss by blocking the attackerâs intrusion. Each round, you will need to choose between 4 actions to prevent the attacker to progress in the network.
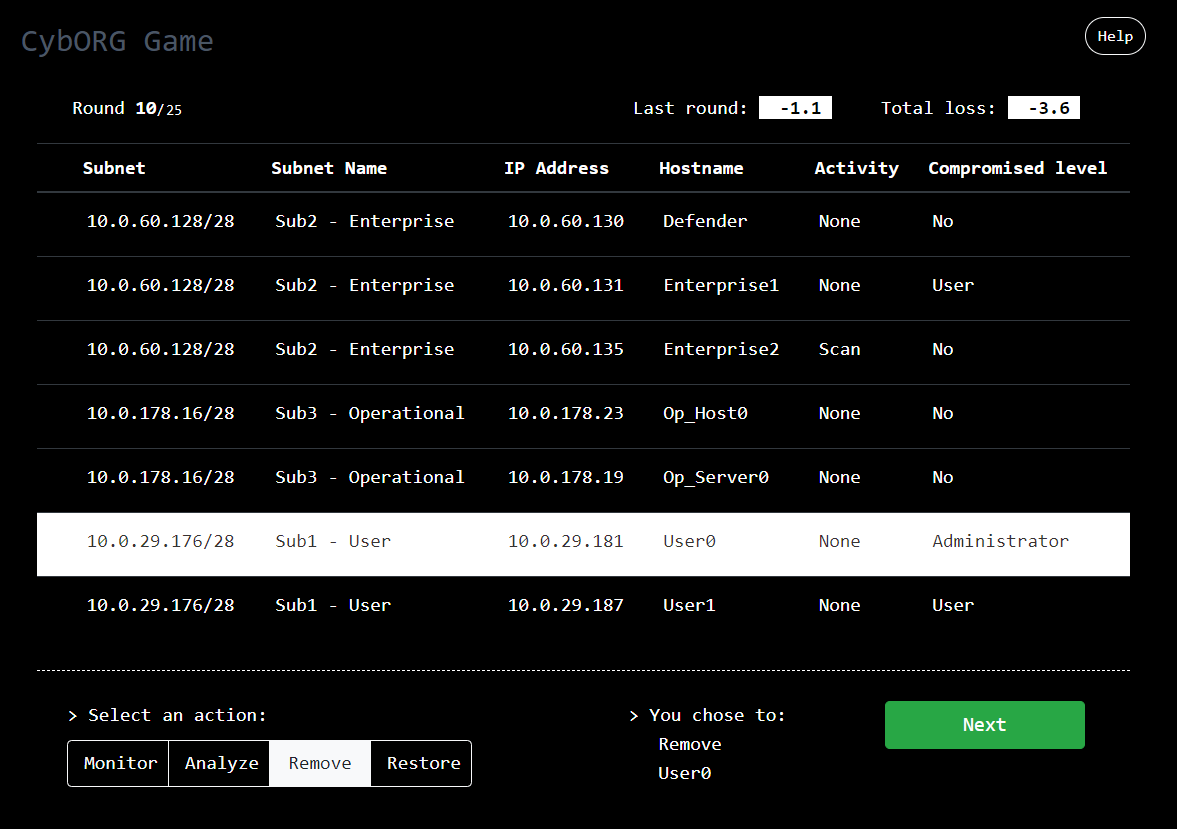
Implemented by: Baptiste Prebot, Yinuo Du, and Tony Xi.
Dynamic Binary Choice
In this activity, you will make simple choices between an âOption Aâ and âOption B.â Each option will either give you 0 or 500 points. There will be 50 of these decisions. There are three versions of this activity you can try. Demo 1, Demo 2, and Demo 3 each vary in the way the probabilities change over time. Could you guess how?

Implemented by: Orsi Kovacs
Treasure Hunting Game
In this treasure hunting game, you will attempt to find treasure in one of two boxes. But it will not be easy! A defender (a computer bot) will attempt to keep you from finding the right box. The defender can defend a box, but only one at a time. To help the defenderâs chances, it may also send you alerts in regards to the boxâs protection status. Sometimes these messages will be true, other times not. Will you succeed?
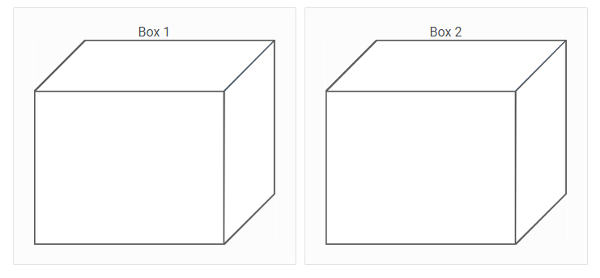
Implemented by: Orsi Kovacs
Rock Paper Scissors
This is our version of the classic Rock, Paper, Scissors game. In twenty rounds, you will make choices and receive points depending on if you win, lose, or tie. Keep the payouts in mind when making your choices!
Implemented by: Frederic Moisan, Updated by: Don Morrison
Dynamic Climate Change Simulator (DCCS)
The DCCS was inspired by generic dynamic stocks and flows tasks, and based on a simplified and adapted climate model. The DCCS interface epresents a single stock or accumulation of CO2 in the form of an orange-color liquid in a tank. Deforestation and fossil fuel CO2 emissions, are represented by a pipe connected to the tank, that increase the level of CO2 stock; and CO2 absorptions, also represented as a pipe on the right of the tank, which decreases the level of CO2 stock.
The absorptions are outside the direct control of the participant. The absorptions depend on the change in concentration of the CO2 stock and the rate of CO2 transfer parameter derived from the models in the previous section.
Implemented by: Varun Dutt
The Water Purification Plant (WPP)
WPP is a resource allocation and scheduling task. It simulates a water distribution system with 23 tanks arranged in a tree structure and connected with pipes. The goal is to go through the purification process on time before the deadlines expire. Decision makers must manage a limited number of resources (only 5 of the 46 pumps available can be active at a given time) over time to accomplish this goal.
With minor modifications, WPP has been used extensively to study automaticity development, stuation awareness, learning, and adaptation. In addition, we developed an ACT-R cognitive model that reproduces human learning in this task.
Implemented by: Cleotilde Gonzalez
Dynamic Stocks & Flows (DSF)
DSF is a generic representation of the basic building blocks of every dynamic system: a single stock that represents accumulation; inflows, which increase the level of stock; and outflows, which decrease the level of stock. A user must maintain the stock at a particular level or, at least, within an acceptable range by contrarresting the effects of the environmental flows.
Implemented by: Verun Dutt and Cleotilde Gonzalez
Beer Game
We have created a learning environment that provides users with an interactive experience of supply-chain management. The supply-chain consists of a single retailer who supplies beer to the consumers (simulated as an external demand function), a single wholesaler who supplies beer to the retailer, a distributor who supplies the wholesaler, and a factory that brews the beer (obtaining it from an inexhaustible external supply) and supplies the distributor.
Beer game is used extensively to study the way decision makers perform when confronted by dynamic complexity (Sterman, 2004). We use the beer game to study learning and adaptation in DDM. In addition, we have developed an ACT-R cognitive model that reproduces initial data collected on human learning (Martin, Gonzalez, & Lebiere, 2004).
Implemented by: Verun Dutt
MEDIC
MEDIC is an interactive tool involving presentation of symptoms, generation of diagnoses, tests of diagnoses, treatments, and outcome feedback. The simulation begins with a patient complaining of symptoms. Each patient has a different initial health level, which continues to fluctuate downward until the patient has been treated or until the patient dies. Since each patient is randomly assigned one of many fictitious diseases, participants must test for the presence of symptoms, each having a different probability of being associated with one of the diseases. Each test returns with a definitive diagnosis (absent or present) after a predetermined time delay for the test to run. The participant provides an assessment of the probability of the presence of the disease. Then, participants can either conduct more tests or administer a treatment. Feedback comprises the actual disease present, the disease the participant believed was present, and a score that represents their accuracy throughout the task.
Implemented by: Jack Lim
FIRECHIEF (developed by Mary Omodei & Alex Wearing)
Firechief is a resource allocation task in which the participant's goal is to minimize the damage caused by the fire to landscape. There are a limited number of the two appliance types (helicopters and firetrucks) used to extinguish fires.
The screenshot shows the fire having already consumed a certain percentage of the landscape (black areas of the screen) and continuing to spread (red dots on the screen). The score is the percentage of landscape that has not yet been consumed by fire. The simulation takes place in real-time and is highly dynamic, the environment changing autonomously as well as depending on the actions of the participant. Resources are limited as the appliances eventually run out of water and may need to be refilled, thus causing a delay in their usage. The player needs to learn how and where to concentrate resources in order to save as much of the landscape as possible.