
PSC’s Neocortex Upgrades to Cerebras CS-2 AI Systems
New Cerebras Systems technology will double capacity, allow larger deep-learning models and data
By Ken Chiacchia
Media InquiriesThe Neocortex high-performance artificial intelligence (AI) computer at the Pittsburgh Supercomputing Center (PSC) has been upgraded with two new Cerebras CS-2 systems, powered by the second-generation wafer-scale engine (WSE-2) processor. The WSE-2 doubles the system’s cores and on-chip memory as well as offering a new execution mode with even greater advantages for extreme-scale deep-learning tasks, enabling faster training, larger models and larger input data.
Neocortex, funded with $11.25 million from the National Science Foundation to date, is supported under the NSF’s Innovative HPC Program, meant to further the field of high-performance computing (HPC) by funding new technologies with innovative approaches. The system now features a groundbreaking integration of two WSE-2’s – an improved new technology that accelerates deep-learning AI with a unique chip architecture – with a powerful HPE Superdome Flex HPC server. By pairing the robustly provisioned HPE Superdome Flex server for massive data handling capability with the two WSE-2’s, the system has unlocked new potential for rapidly training AI systems capable of learning from vast data sources.
“We are extremely excited to welcome the CS-2 servers into Neocortex,” said Paola Buitrago, principal investigator of Neocortex and Director, Artificial Intelligence & Big Data at PSC. “This upgrade enhances support for new models, algorithms and research opportunities. We look forward to the breakthroughs that the now even greater capabilities of Neocortex would enable. We will continue working with the research community to help them take advantage of this technology that is orders of magnitude more powerful.”
The CS-2 is based on the innovative WSE. The WSE-2 is the largest chip in existence and is the fastest AI processor. Whereas traditional processors are the size of postage stamps, the WSE-2 is the size of a dinner plate. In AI, big chips process information more quickly, producing answers in less time.
In deep learning, an AI program represents characteristics of a computational problem as layers, connected with each other by lines of inference. The AI first trains on data in which humans have labeled the “right answers,” pruning or strengthening inference connections until it is predicting correctly. The researchers then test the AI against a dataset without such labels, to grade its performance. Finally, once the AI is performing adequately, it can be set to the task it has been designed to address.
The two-dimensional grid of cores on the WSE-2 allows the system to route machine-learning tasks in physical space, essentially reproducing the layers of a deep-learning algorithm on different parts of the chip. By leveraging a 7-nm fabrication process, the CS-2 improves upon the CS-1’s capabilities by expanding the number of cores from 400,000 to 850,000 and on-chip memory from 18 GB to 40 GB. The CS-2 does this with the same footprint, power, and cooling requirements as the CS-1.
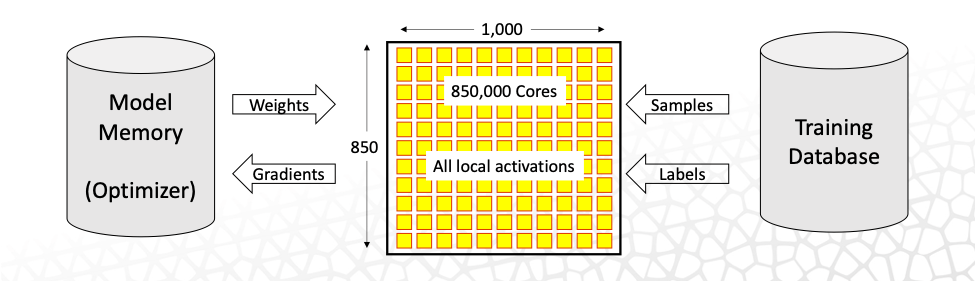
In addition to the above, “pipelined” execution mode present on the CS-1, the CS-2 will offer a “weight streaming” mode for very large models and data. In the pipelined mode, the entire model is mapped onto the WSE-2 at once, with each layer of the model getting a portion of the wafer. This arrangement leverages activations and data sparsity with very low latency, an approach that works well for most deep-learning models. With weight streaming, one layer of the network is loaded onto the CS-2 fabric at a time, leveraging dynamic-weight sparsity. Thus the model is arranged in time rather than space, with weights instead of activations streaming. This approach offers industry leading performance for extreme-scale models and data inputs.
“The principal difference is what’s kept stationary on the wafer and what’s streaming through the wafer,” said Natalia Vassilieva, Director of Product, Machine Learning at Cerebras Systems. “The compiler will pick the proper execution mode depending on the size of the model.” She added that users will in the future also be able to choose the mode.
The CS-2 servers have been deployed and tested at PSC. Access to Neocortex is offered at no cost for open science research. Those interested in gaining access to the system are encouraged to consult the official project website (https://www.cmu.edu/psc/aibd/neocortex/) for more details and to get in contact.