Big Data Accelerates Biodiversity Research
- Dietrich College of Humanities and Social Sciences
- 412-268-9309
Museums hold the storehouse of specimens required to understand biodiversity across the planet. These archives serve as historical snapshots of biodiversity in one area, at one time. While this information has historically remained isolated, recent efforts to digitize collections have produced a bridge between these rich troves, combining collections into a larger pool that researchers can tap to tackle deep questions about global biodiversity.
"Datasets from thousands of museums across the globe are increasingly digitized and accessible in publicly searchable, online data portals," said Mason Heberling, assistant curator of botany, co-chair of collections at Carnegie Museum of Natural History and first author on the study. "We are increasingly swimming in high volumes of data, but accessing and making sense of these data can be the limiting challenge."
Heberling consulted experts at the Digital Sciences, Humanities, Arts: Research and Publishing (dSHARP) coalition at Carnegie Mellon University. A team of faculty and staff in University Libraries and the Dietrich College of Humanities and Social Sciences, dSHARP is dedicated to advancing research and teaching involving digital tools, methods and sources.
Heberlin's collaboration with dSHARP resulted in a paper titled "Data integration enables global biodiversity synthesis" published in the February issue of Proceedings of the National Academy of Sciences.
"This is a great example of how digital humanities can collaborate with the sciences," said study co-author Scott Weingart, program director for the Digital Humanities at CMU. He said collections are often based on time, place or populations. "This [database aggregates] all of the information together so biodiversity science can make broader and more global claims."

Mason Heberling

Scott Weingart
"This is a great example of how digital humanities can collaborate with the sciences." — Scott Weingart
Big Data, Big Results
Heberling and Weingart used a machine-learning algorithm on more than 4,000 research articles published between 2003 and 2019 to quantify the scientific impact of the Global Biodiversity Information Facility (GBIF), the largest open-access biodiversity research database. Weingart and Heberling were joined by Joseph T. Miller, Daniel Noesgaard and Dmitry Schigel of GBIF on the project, and the work received funds from the GBIF Secretariat.
The team found that the data available through the GBIF has increased by more than 1,150% in the past decade. This explosion in data is due in part to the participation of citizen scientists, who collect and input information into the database. In addition, research generated from GBIF-mediated data increased during the past decade, from 148 studies published in 2003-2009 to 723 studies published in 2019. Finally, they found that GBIF-enabled research extends across all major scientific disciplines.
"Combining community science-generated data and digitized museum records has been profound in understanding basic biology and the local to global impacts of environmental change," Heberling said. "We show that making these data freely available in a single platform not only makes biodiversity discoveries more efficient, but also enables new research that wouldn't otherwise be possible."
The team also found the legacy of scientific colonialism in the modern aggregated environmental dataset.
"In some ways, we are seeing GBIF reinforces this history," Weingart said. "Certain countries are exporters of scientists and importers of data."
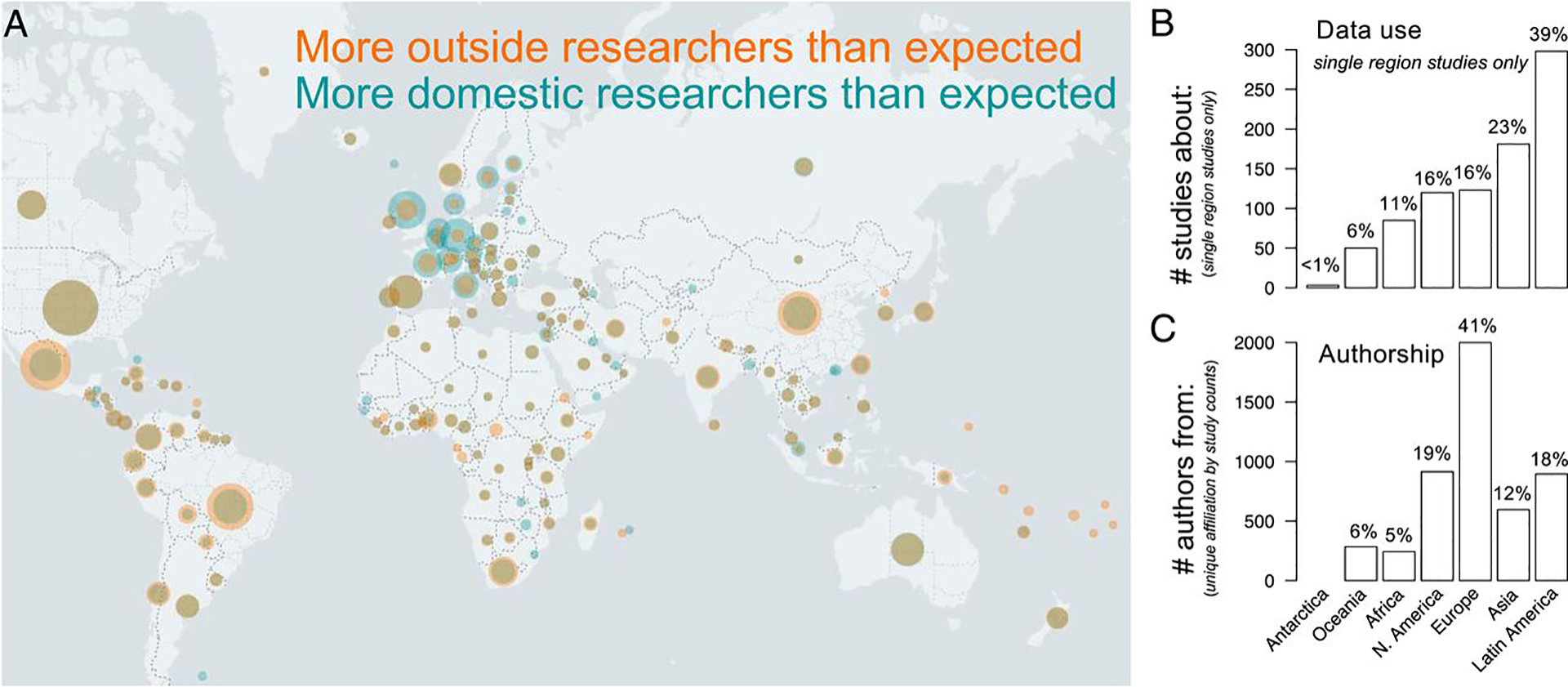
Geography of GBIF data use and authorship. The map highlights disparities between country-level biodiversity data use and author affiliation. Orange circles indicate country-level biodiversity data use, and teal circles indicate country-level author affiliations. Researcher affiliation is overlaid atop research coverage to form brown where they overlap. Wider teal rings indicate disproportionately higher number of researchers than research specific to that country (e.g., United Kingdom), whereas wider orange rings (e.g., Mexico) indicate the opposite. Brown circles with no external rings indicate a proportionally similar number of studies about a given country to authors from a given country (e.g., United States). The bar charts show the corresponding frequency of studies published in 2016 to 2019 about a specific region, excluding global studies and the frequency of authorship from each region.
The researchers found that many of the biodiversity studies were conducted in regions across the southern hemisphere but authored by researchers from countries in the northern hemisphere. In particular, large amounts of data were collected from Latin America but gathered by researchers from European institutions. While progress has been made in getting more local experts involved, nearly 8% of regional studies were completed without authors from the study location, who could add nuance to the study results.
"Though legacies of scientific colonialism persist, the open access integration of data shows promise towards a more global and diverse research community," Heberling said. "By making these data publicly available online, these specimens are digitally repatriated back to the region they came from."
More Data, Please
Heberling said this review is far from complete. The study highlights the value of large, international databases, and the need for continued efforts to develop a new era of data-intensive biodiversity science that embraces information from a variety of fields, including environmental sciences and policy, evolutionary biology, conservation and human health.
"Our review demonstrates the scientific and societal value of combining freely available biodiversity data from many different sources," Heberling said. "We hope our analysis encourages new uses of these data."