
Hating who? Exploring differences in hate speech by target
By Michael Miller Yoder
Photo Credit: Jon Tyson, Unsplash https://unsplash.com/photos/IYtVtgXw72M
Citation and Link to associated Paper:
- Michael Yoder, Lynnette Ng, David West Brown, and Kathleen Carley. 2022. How Hate Speech Varies by Target Identity: A Computational Analysis. In Proceedings of the 26th Conference on Computational Natural Language Learning (CoNLL), pages 27–39, Abu Dhabi, United Arab Emirates (Hybrid). Association for Computational Linguistics.
Tags: hate speech; natural language processing; identity
Social media and online forums have become the latest domains to spread rhetoric that targets people and groups based on their identities. This discourse has serious offline consequences, inspiring attacks on marginalized groups from Pittsburgh in 2018 to Buffalo in 2022.
To handle hate speech at the scale of social media, tech companies turn to automated methods to detect content that might be considered hate speech. However, detecting hate speech is a complex problem. This is in part because of a lack of consensus about what is considered hate speech, which usually includes a variety of content from calls to violence to racist jokes. Automated methods of hate speech detection using machine learning and natural language processing (NLP) usually ignore this variation. Classifiers often simply predict "hate speech" or "not hate speech" regardless of what identity group is targeted.
We investigated how hate speech differs by which identity group is targeted. Scholars working in fields such as linguistics and philosophy often point out these differences, and activists have called for tech companies to consider these differences and prioritize hate against marginalized groups. What effects, if any, does this variation have on automated hate speech classification? Which identity groups have similar hate speech directed toward them?
To answer these questions, we started with the raw data that is often used to build hate speech classifiers: social media posts labeled by annotators as hate speech or not hate speech. We examined several datasets across different social media domains where annotators also labeled which identity group was targeted by the hate speech. Separating the data based on targeted identity, we trained NLP classifiers on data targeting one identity group and tested it on data targeting other groups. If hate speech targeting different groups was largely similar, these classifiers would perform well regardless of which identity the hate speech was targeting. We found that they did not generalize well at all (results below).
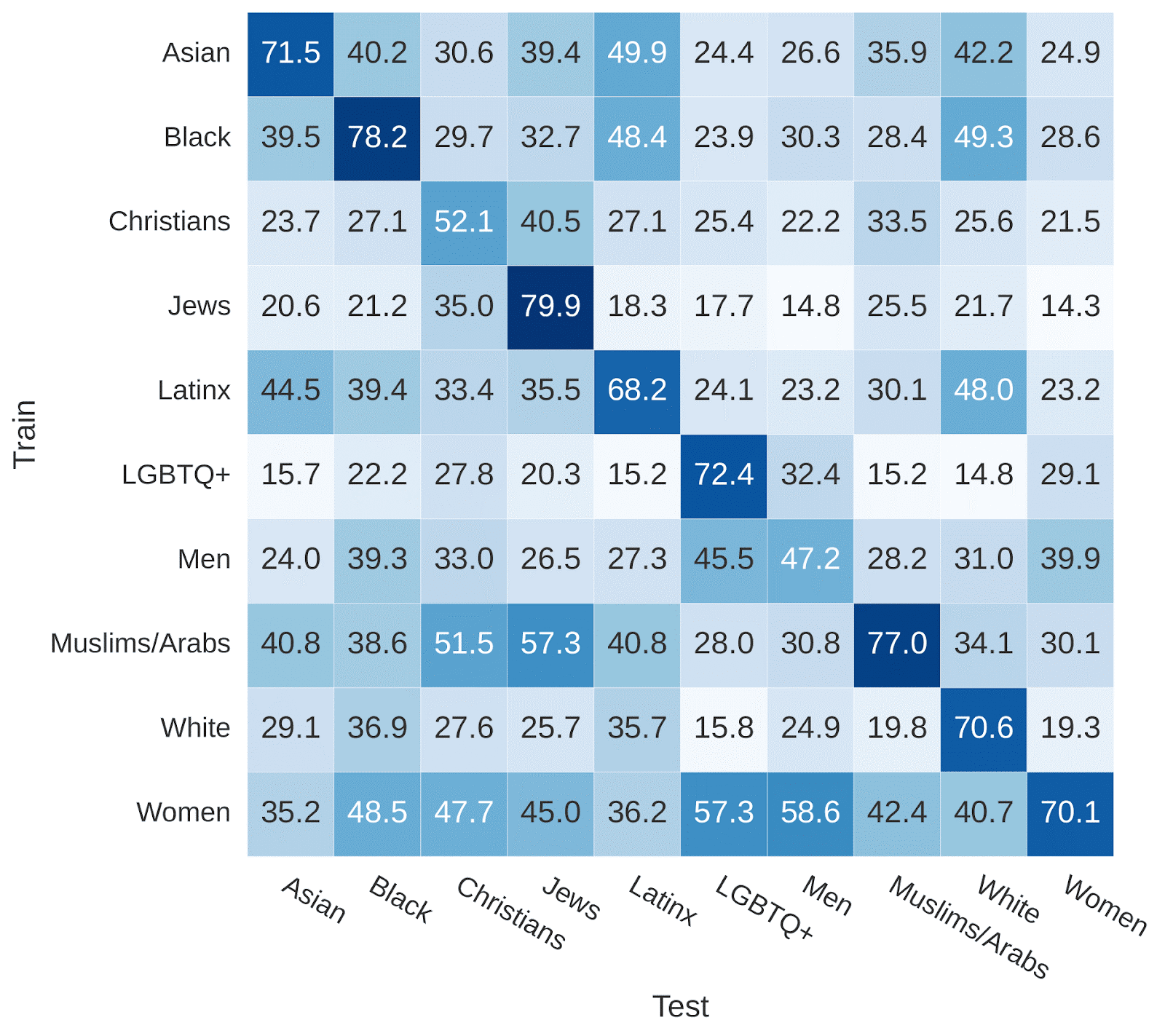
Credit: Michael Miller Yoder, Lynnette Ng
Caption: Hate speech classification performance (F1 score on hate speech) when training and testing on data targeting different identity groups
Since classifiers trained on hate speech toward one target identity often perform poorly on other target identities, those building hate speech classifiers need to consider which identities are targeted in their data. These results also provide evidence that the language of hate speech directed at these different identity groups is different enough that hate speech classifiers struggle to recognize hate speech directed at identities they haven't seen before.
Is this variation random, or are there patterns in similarities and differences among hate speech directed at different targets? We considered variation among targeted identities along 2 different dimensions: which demographic category the identity group references (such as race or gender), and how much relative social power the identity group has had in the European and North American contexts in which the datasets we look at have been collected.
The following graph is a visual representation of similarities in generalization performance using a statistical technique called PCA on the previous results matrix. PCA allows relationships between vectors to be visualized in 2 dimensions (the particular values of these dimensions do not matter as much). This allows us to see which groups perform similarly when trained on hate speech directed toward them and tested on hate speech toward other identity groups.
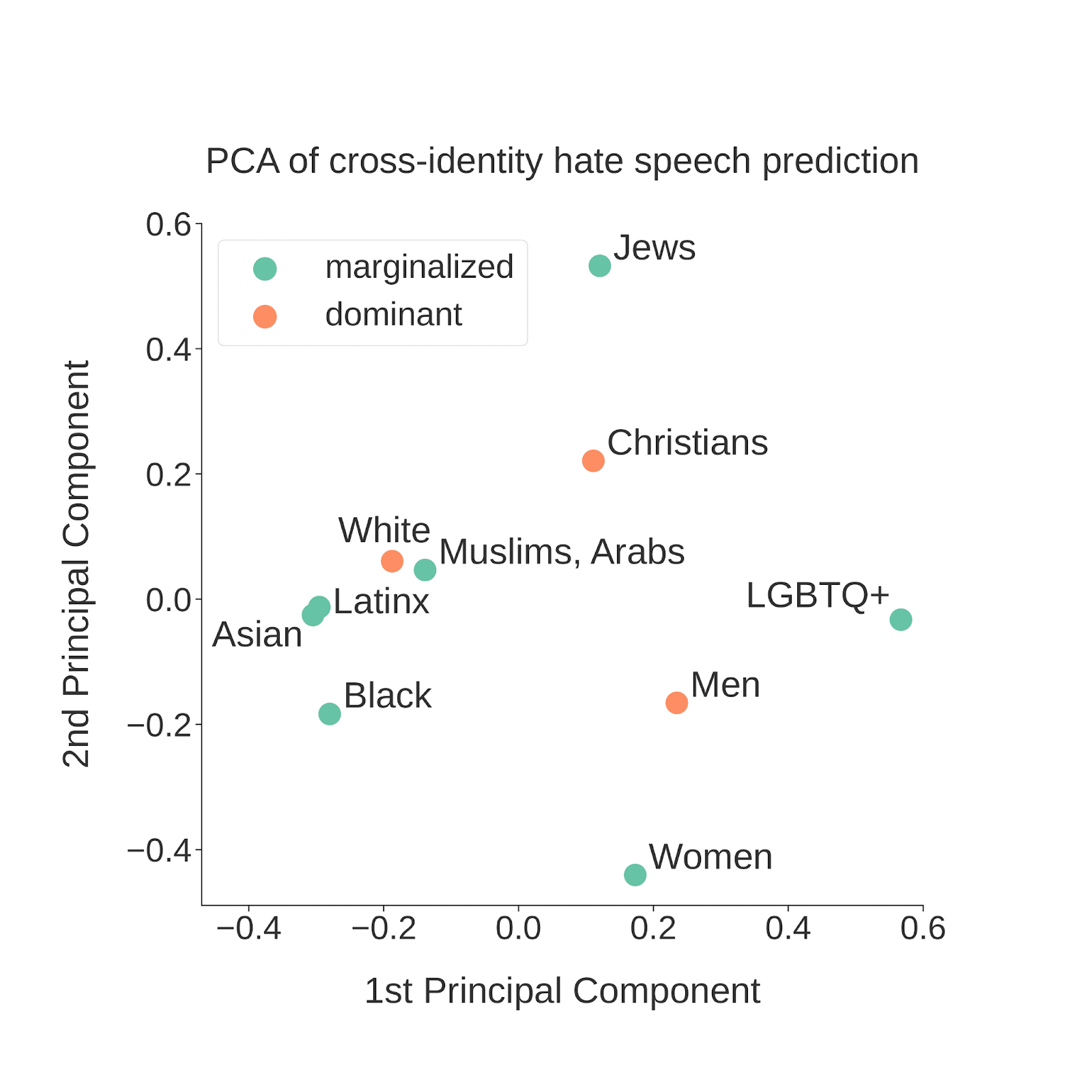
Credit: Michael Miller Yoder, Lynnette Ng
Caption: Visual representation of similarities and differences between hate speech directed at different identity groups
Points on this graph are colored based on the relative social power of identity groups into two coarse-grained categories, "marginalized" and "dominant". However, it is apparent that the more prominent distinction among identity groups seems to be demographic category: groups that are based on religion seem to be near the top right, while groups based on race and ethnicity are toward the left, and groups based on gender and sexuality are toward the bottom right.
To further test which target identity dimension appears to have a larger effect on hate speech, we group identities by either demographic category or relative social power and repeat generalization experiments. We find that performance drops more sharply across hate speech targeting different demographic categories than across groups that differ by social power.
Hate speech variation by social power deserves a closer look. Should hate against socially dominant groups such as white people and men be considered in the same category as more prototypical hate speech against marginalized groups such as Black people or transgender people? Scholars in language and philosophy note how hate directed at dominant groups does not cue up the same history of oppression and identity-based violence as does hate speech against marginalized groups (see Judith Butler's Excitable Speech and Chapter 3 of Robin Tolmach Lakoff's The Language War. With these differences, what if NLP hate speech datasets did not include hate speech toward dominant groups? Would there be a clearer signal for classifying hate speech without this data, which could act as noise?
We test this by removing hate speech against dominant identities, such as white people, men, and Christians, and then training and testing hate speech classifiers. Though most datasets do show some improvement when hate speech against these groups are removed, few of these differences are significant. Removing random target identities from consideration also produces significant improvements in some datasets. In summary, we do not find conclusive evidence that hate speech against dominant identities is different enough from other forms of hate speech that removing it leads to better classification performance. Differences in hate speech toward identity groups with relative social power is likely experienced by those interpreting the hate speech with knowledge of the social context rather than affecting the language enough to confuse classifiers.
Our results suggest that there are significant differences in hate speech depending on which identities are targeted. So what are these differences?
To explore these differences, we use a tool called SAGE to find which words are most representative of particular sections of a text dataset. In our case, the sections are hate speech directed at different identities. Unsurprisingly, we found that identity terms, many of them abusive and derogatory, made up many of these representative terms. But we also found something interesting about the remaining representative terms. They often involved social context that was specific to the identity involved. For example, these terms sometimes evoked histories of oppression, such as Holocaust references in anti-Jewish hate speech. Other times they referenced harmful stereotypes, such as between terrorism and Islam. Still other times these terms referenced current events and culture war issues, such as "bathroom" in anti-LGBTQ+ hate speech and "BLM" in anti-Black hate speech. This lexical analysis reinforces that differences among hate speech by targeted identity relate to the particular social contexts and associations made with those identities.
What are the implications of these results? At the bare minimum, those designing hate speech classifiers should consider the distribution of targeted identities in the data they are using for training. This information is not available for many datasets, which is also a problem. If a hate speech dataset mostly contains Islamophobia, classifiers trained on it will likely have a difficult time detecting anti-LGBTQ+ hate speech, for example. Our results suggest that these differences will be particularly a problem across targeted demographic categories. We should be more nuanced than simply labeling data as hate speech or not, since the category of hate speech contains lots of internal variation. One of the important dimensions of variation to consider is which identities are targeted. We also found that these differences often relate to the specific social and historical context of identity groups in societies. How to incorporate knowledge about this social context into automated machine learning classifiers remains an open, important question.