Identifying Cross-Platform Relationships in 2020 US Election Discussions
By Isabel Murdock
Tags: Social media networks; Multi-platform; Election
Recent Publication:
Isabel Murdock, Kathleen M. Carley, and Osman Yağan. 2023. "Identifying cross-platform user relationships in 2020 U.S. election fraud and protest discussions", Online Social Networks and Media (OSNEM), vol. 33, pp. 100245. https://doi.org/10.1016/j.osnem.2023.100245
As social media has grown in popularity over the past decade, so has the number of social media platforms available to users. These platforms provide unique social structures and posting mechanisms that control how users connect and share information. Additionally, many users engage with multiple social media websites, and in doing so, they provide pathways to spread information between communities on different platforms.
This new publication analyzes how information spreads over multiple social media platforms. It explores five approaches for identifying and characterizing users who actively support such information diffusion and applies them to a 2020 U.S. election dataset involving Twitter, Facebook, Reddit, and Instagram. The work focuses on three main goals:
- To identify social media users on different platforms who appeared to intentionally spread the same information over multiple platforms or transfer information between platforms.
- To characterize the political bias and fact ratings of the users engaged in multi-platform behaviors.
- To compare the performance of URLs spread by the identified users to the complete dataset.
- Identification of users across platforms
We explored five approaches for identifying cross-platform pairs of users involved in the diffusion of URL-based content over multiple platforms. The approaches differed in either how they identified the cross-platform user pairs or in the types of relationships they aimed to identify. The features considered by the identification approaches were the similarities of usernames and display names and the timing and order of URL postings. Rather than using a combination of these approaches, we examined each individually to compare the user networks obtained through each method and the types of content each group shared.
All the approaches we studied returned user pairs in the 2020 U.S. election dataset, which contained 24M social media posts (results below). Most of the identified relationships were between Twitter and Facebook users. This is consistent with our finding that the two platforms had the largest overlap in URL content out of all of the combinations of platforms.

Once we had obtained user pairs for each of the five identification approaches, we used multiple methods to validate the results. First, we constructed three null models of user posting behaviors. This allowed us to compare the number of user pairs identified in the dataset to those that might be identified if users acted independently across platforms. From this analysis, we concluded that the identification approaches that relied solely on URL posting behaviors (i.e., the bidirectional introducers, repeat introducers, and synchronized users approaches) appeared to identify more relationships than would be expected to occur from coincidences in postings alone.
The second form of validation involved the structures of user-to-user networks that resulted from each of the five identification approaches. Since the goal of the same name users and bidirectional introducers approaches was to identify relationships between the same individual or organization across multiple platforms, we expected the user networks from those approaches to be composed of small components. While some organizations may operate a few different pages on a given platform (e.g., for different teams or sectors of their business), finding large components in the resulting networks would suggest that the same name users and bidirectional introducers approaches were not successful in only identifying individual organizations or entities.
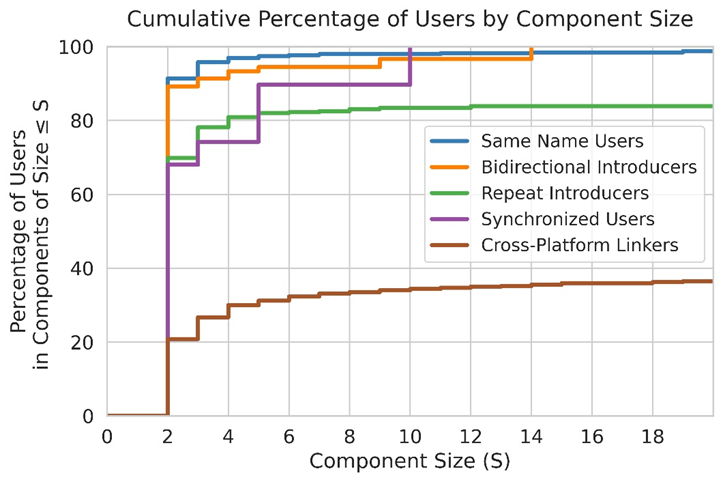
In alignment with our expectations, we found that the same name users and bidirectional introducers approaches yielded user networks with at least 90% of users in components of less than four users (see figure below). The user networks from the repeat introducers, synchronized users, and cross-platform linkers approaches had smaller percentages of users in dyads and triads. Since these three approaches intended to find a broader class of cross-platform relationships, including those resulting from bots and one-way cross-platform behaviors, it makes sense that larger components would arise in these networks.
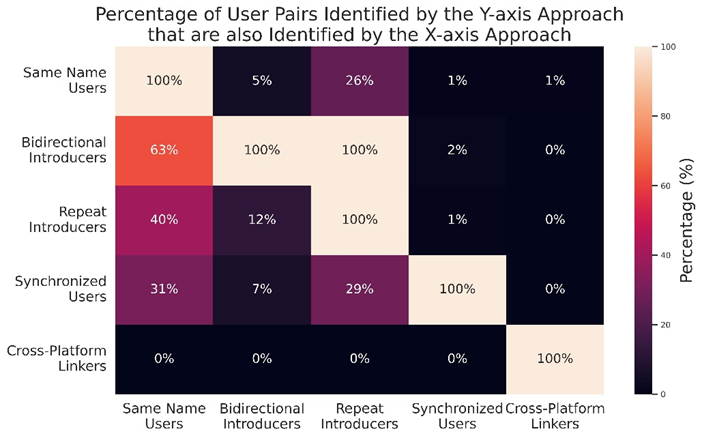
The third method used to validate the results involved measuring the overlaps in edges between the different user networks (see heatmap below). We found that the same name users approach also identified 63% of the user relationships identified by the bidirectional introducers approach. As these two approaches intended to find the same types of relationships, this supports the conclusion that the pairs identified are the same user or individual acting on multiple platforms. Meanwhile, the fact that it was not a complete overlap suggests that the bidirectional introducers approach identified additional accounts that did not share similar names but may still be the same individual or organization. In repeating this analysis with the remaining combinations of identification approaches, we found that the different approaches identified unique sets of user relationships that would not have been found using a single approach alone.
- Characterization of political bias and fact tendencies
Regarding the content the users posted, the same name users, bidirectional introducers, and repeat introducers posted URLs linking to news articles the most, followed by political opinion and blog-type websites. Out of these three approaches, the same name users had the smallest percentage of links to political opinion content. This could indicate that the same name users were more likely to be news organizations. Conversely, the synchronized users linked to political blogs and commentary websites far more than news organizations. This suggests that the synchronized users approach may have identified users with different goals and content preferences.
As for political biases, we find that the synchronized and cross-platform linking users were more right-leaning than the rest (see figure below). Combined with the content findings, we conclude that the synchronized users were mostly engaged in promoting content linking to right-leaning political blogs and commentary websites. Meanwhile, the same name users primarily linked to left-leaning mainstream news sources, while the bidirectional repeat introducers tended to introduce content from less biased mainstream news sources.
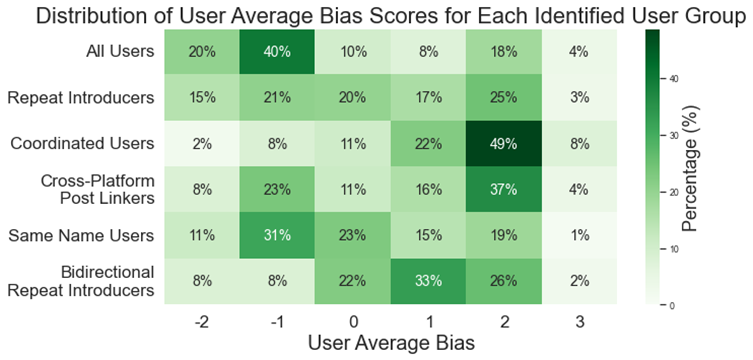
The distributions of factual information scores for the users in each group also highlight the synchronized users for posting low factual information. Furthermore, we found that the same name users and bidirectional repeat introducers had the biggest shares of users with high factual information scores, indicating that these pairs of users were sharing URLs linking to higher credibility websites.
- Comparison of URL performance
The URLs introduced to their respective platforms (i.e., posted for the first time) by the bidirectional and repeat introducers underperformed relative to the content posted by the rest of the identified users. They tended to be posted less and have shorter posting life spans. Although they had faster posting speeds and may have appeared to spread quickly across the platforms, this more likely resulted from the URLs being posted fewer times in a shorter period rather than being more viral.
The URLs posted by the same name users performed similarly to the full set of multi-platform URLs in the dataset, except for having shorter posting life spans. Meanwhile, the synchronized users’ URLs had the most unique performance characteristics of all the URL subsets. This is likely due, in part, to the relatively small number of URLs posted by the synchronized users. Unlike the rest of the user pairs, a large share of the synchronized users’ URLs, more than 30%, received over 100 posts. They also tended to have the fastest postings speeds and were the most likely to be posted again after multiple 24-hour breaks in being posted.
These findings suggest that while the URLs introduced by the repeat and bidirectional introducers tended to perform worse than the rest, the user pairs identified by those approaches tended to generally post content with similar performance to those posted by the same name user pairs. It also indicates that the synchronized users were mostly involved in spreading well-posted and likely popular content.
Conclusions
In this work, we draw on prior cross-platform user identification and user coordination research to explore five approaches for identifying pairs of cross-platform users engaged in multi-platform content-spreading behaviors. These approaches differed in either the attributes and behaviors they leveraged to identify the user pairs or in the types of relationships they aimed to uncover. In doing so, they did not rely on the social media platforms of study having similar social structures or public users, but instead on URL-posting being a common practice on the platforms.
Within the context of fraud and protest discussions surrounding the 2020 U.S. election, we used the outlined approaches to perform a case study of four social media platforms. The evaluation of each method independently revealed that the users identified by the different approaches shared different types of content, with different political biases and factual ratings, and posted URLs with varying degrees of spreading performance. This suggests that if practitioners are interested in identifying a particular type of multi-platform actor (e.g., news organizations) or comparing behaviors across different types of actors, it may be advantageous and more efficient to use individual identification approaches. On the other hand, if researchers are interested in building a set of possible cross-platform actors, they may use a combination of the approaches. Finally, if they want to minimize false positives when identifying pairs of cross-platform users, an effective approach may be to require the users to display behaviors from multiple approaches.
Ultimately, this work can be used to help identify and characterize users who facilitate multi-platform content diffusion and highlights the importance of studying the spread of information across multiple social media platforms. Further investigation is needed within additional contexts and platforms to evaluate the types of users identified by the approaches presented here and to measure the role that such users play in facilitating multi-platform content spread.