CMU Algorithm Wins International Strong Lens-Finding Challenge
Project brings together Carnegie Mellon's expertise in cosmology and machine learning

In the center of this image, taken with the NASA/ESA Hubble Space Telescope, is the galaxy cluster SDSS J1038+4849. In this "happy face," the two eyes are very bright galaxies, and the misleading smile lines are arcs caused by an effect known as strong gravitational lensing.
An interdisciplinary team of researchers from Carnegie Mellon University's McWilliams Center for Cosmology has combined the university's expertise in astrophysics and machine learning to win an international strong lens-finding challenge organized by the European Space Agency's Euclid strong lensing working group.
"We were not the only team using machine learning in this challenge, but the fact that our algorithm ultimately won is a tribute to the quality of interdisciplinary research here at CMU, especially between astrophysics, computer science and statistics," said François Lanusse, a post-doctoral researcher in Carnegie Mellon's Department of Physics.
The challenge asked research groups to develop an automated method to find galaxies that were strongly bending light. In this phenomenon, called strong lensing, one large galaxy is situated directly in front of a second galaxy, causing the light from the second galaxy to bend and form an arc around the first galaxy. The shape of the arc can be used to determine how all matter, including dark matter, is distributed in the lensed galaxy.
"These rings, called Einstein rings, are a distinct feature, but can be hard to pick out of large astronomical datasets," said Rachel Mandelbaum, associate professor of physics who advised the team together with Assistant Professor of Machine Learning Barnabás Póczos. "Strongly lensed galaxies are quite rare, and we need a reliable, automated way to find them."
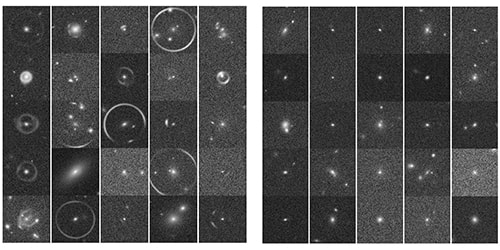
CMU DeepLens was able to discern between strong gravitational lenses (left) and objects that are not lenses (right).
The next generation of sky surveys, including the ground-based Large Synoptic Survey Telescope project (LSST), the space-based Euclid survey and NASA's space-based Wide Field Infrared Survey Telescope (WFIRST), will collect unprecedented amounts of data. Automated methodologies for sorting through this data to find interesting astronomical objects to study is essential. For example, there will only be a few hundred thousand to one million strongly lensed galaxies out of an estimated 20 billion galaxies in the LSST's data; finding one without the help of automation would be like finding a needle in a haystack.
For the challenge, the organizers created a simulated data set that contained information about strong-lens systems and systems that looked like they were strongly lensed, but were not. They asked competitors to create a method that could accurately identify strong lens candidates.
Lanusse and machine learning graduate student Eric Ma turned to deep learning, a field of machine learning that has had a great deal of success in image recognition problems, to attack the challenge. Their algorithm, CMU DeepLens, accurately identified the most strong lensing candidates within the data set, and had the least amount of errors. The results were especially striking given that many of the other algorithms entered in the competition had taken years to develop, and Lanusse and Ma developed their algorithm in less than two weeks.
"Our algorithm was amazingly powerful and capable of a high level of sophistication. It did a great job of discriminating between true strong lens systems and false data, and did better than human classification," Mandelbaum said.
CMU DeepLens is especially promising because it can work with cosmological data containing color information and data that does not. This is important because space-based surveys like Euclid do not collect color data, but ground-based surveys like the LSST can. The researchers have made the algorithm freely available, and hope that it will be used to analyze available and future cosmological data.
Machine learning post-doc Siamak Ravanbakhsh, machine learning graduate student Chun-Liang Li and others contributed to the development of CMU DeepLens.