DataShop
DataShop offers learning science researchers a sophisticated data analysis service for fine-grained, longitudinal datasets.
DataShop also serves as a secure data repository for educational research. It was recently expanded with the launch of DataLab, creating the world's largest bank of educational technology data.
DataShop is funded by a National Science Foundation grant (SBE-0836012) to LearnLab, the Pittsburgh Science of Learning Center. Previously it was funded by NSF award number SBE-0354420.
How is DataShop used?
Researchers have utilized DataShop to explore learning issues in a variety of educational domains. They can, for example, determine if students are learning by viewing learning curves, then drill down on individual problems, knowledge components and students to analyze performance in greater detail. Examples include:
- Collaborative problem solving in Algebra
- Self-explanation in Physics
- The effectiveness of worked examples and polite language in a Stoichiometry tutor
- The optimization of knowledge component learning in Chinese.
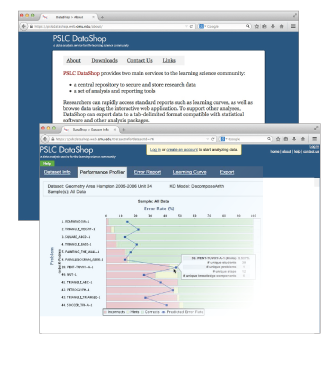
What data is available in the repository?
DataShop and DataLab hold more than 705,000 hours of student data across 1466 datasets , collected from 358,000 students who used online courses, intelligent tutors, simulators and educational games.
The data contains three attributes that make it particularly useful for educational data mining analyses.
- First, the data is fine-grained — containing semantically meaningful transactions between the student and the software, including both the student's action and the software's response.
- Second, the data is longitudinal — spanning student behavior and learning, in many cases, over an entire semester or year of study.
- Third, the data is extensive — involving millions of transactions for some of the educational software packages for which DataShop has data.
What domains does the data cover?
Data has been contributed by Carnegie Mellon University's LearnLab courses, the ASSISTments project and the Open Learning Initiative as well as by other researchers. A snapshot of the datasets currently in the repository include the following, broken out by domain:
| DOMAIN | DATASETS | STUDENT ACTIONS | STUDENTS | STUDENT HOURS |
| Languages | 137 | 12,423,000 | 14,592 | 27,937 |
| Math | 422 | 142,005,000 | 172,388 | 378,401 |
| Science | 255 | 30,088,000 | 64,987 | 91,012 |
| Other / Unspecified | 652 | 66,155,000 | 106,033 | 208,6333 |
| Total | 1466 datasets | 250,671,000 actions | 358,000 students | 705,983 hours |
Datasets are continually being added by DataShop's user community, which is free and open to anyone in the learning science community.
What types of data can DataShop store?
DataShop can store a wide variety of types of data associated with a computerized course or study. This includes student-software interaction data (which is capable of being analyzed through DataShop's tools) as well as any related publications, files, presentations or electronic artifacts a researcher would like to store.
In many cases, pre- and post-tests, questionnaire responses, system screen shots and demographic data are associated with student interaction data. Mappings between problem steps and knowledge components (either skills or concepts) can be created by researchers and statistically compared to one another.
How can I use DataShop?
DataShop access is free, but you'll need to create an account in order to view public datasets and upload and save your own data. (Users have the option to keep datasets they upload private. You can request access to private datasets from the project's principal investigator and data provider.)