
Custom Condition Generation for Zero-Shot Human-Scene Interactions Synthesis
By Ashlyn Lacovara
A collaboration between Fujitsu and Carnegie Mellon University Robotics Institute has led to the development of a new method for generating human-scene interactions, effectively overcoming the challenges faced by existing techniques in handling uncommon interactions. This innovative approach leverages the strengths of large language models (LLMs) and vision-language models (VLMs) to create tailored conditions for generating interactions without relying on previously seen examples, utilizing a zero-shot synthesis method.
Accurately simulating a wide variety of human-scene interactions is crucial for the advancement of augmented reality, virtual reality, digital twin technologies, computer games, and data augmentation. Traditional methods often fall short in generating diverse interactions due to their reliance on costly ground-truth data, which limits the variety of actions and scenes that can be effectively modeled and reproduced.
While zero-shot synthesis methods address this issue, existing techniques are effective in generating standard interactions, such as "opening a door" or "sitting in a chair," where the actions are common and well-supported by existing datasets. These methods can leverage predefined models and data to simulate these interactions accurately. However, they struggle with less frequent interactions, such as "kicking a table" or "hand-standing on a chair," where the actions are less typical and require a deeper understanding of the scene and context. The reliance on input images and their contained objects further limits the ability to generate these uncommon interactions. Addressing these rare interactions is crucial for real-world applications, where systems must anticipate and respond to diverse and unexpected human behaviors that are not adequately represented in current datasets.
The researchers' new zero-shot human-scene interaction generation method follows a comprehensive three-step process designed to address these limitations. First, they generate a preliminary human posture using VLMs and text that describes the target interaction, which is then estimated in three dimensions. This step ensures that the generated posture aligns with the text description, avoiding training data bias and allowing for diverse postures. Next, they refine the conditions to fit specific scenes and interactions through analysis with both LLMs and VLMs. This involves generating custom conditions to achieve plausible positions and orientations for each interaction, utilizing VLMs' image analysis capabilities and LLMs' knowledge. Finally, they fine-tune the placement, orientation, and posture of the human figure using specific optimization techniques, defining loss functions based on these conditions to refine the generated interactions.
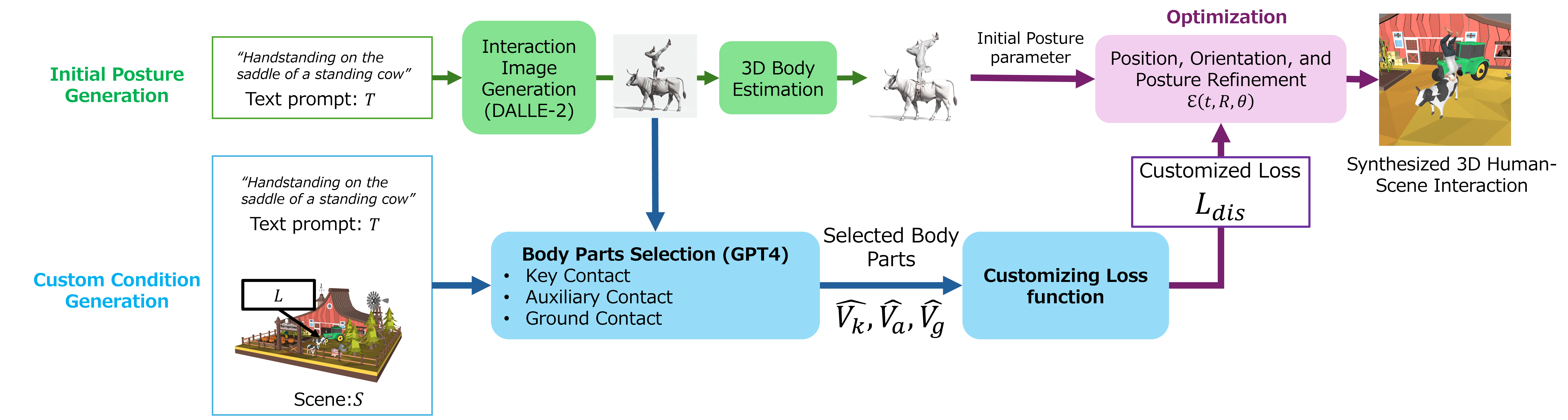
This figure shows an outline of our method: In the initial posture generation step, an interaction image is generated using DALLE-2, and 3D posture parameters are estimated. In the custom condition generation step, GPT-4 analyzes the image, text prompt, and scene to identify contact body parts for customizing loss functions. Finally, a 3D human is synthesized by optimizing these customized loss functions to ensure a realistic 3D human interactions.
Experimental results show that this method excels in generating a wide range of interactions, including less common ones. This approach synthesizes diverse and realistic human-scene interactions across various scenarios, demonstrating its potential to transform the field.