
GHOST: Context-Aware Human Motion Generation in 3D Environments
By Ashlyn Lacovara
Researchers at Fujitsu and Carnegie Mellon University Robotics Institute, have collaborated on a new project called GHOST: Grounded Human Motion Generation with Open Vocabulary Scene-and-Text Contexts. Their work focuses on creating human movement in 3D environments by leveraging text descriptions that relate directly to the surroundings.
Human pose and motion generation in 3D scenes is essential for industries such as visual effects, video games, virtual and augmented reality, and robotics. This technology enables the creation of realistic and expressive human animations that accurately reflect the environment and interactions. By taking into account the shape, lighting, and physical features of a 3D scene, human movements can blend smoothly with the setting, resulting in engaging and visually consistent animations. A significant challenge in this domain is achieving precise control over these animations.
Recently, advances in text-conditional generation, the process of generating text using a machine learning model where the output is specifically tailored based on a given text prompt, sparks a significant change in creating synthetic data in these various areas.
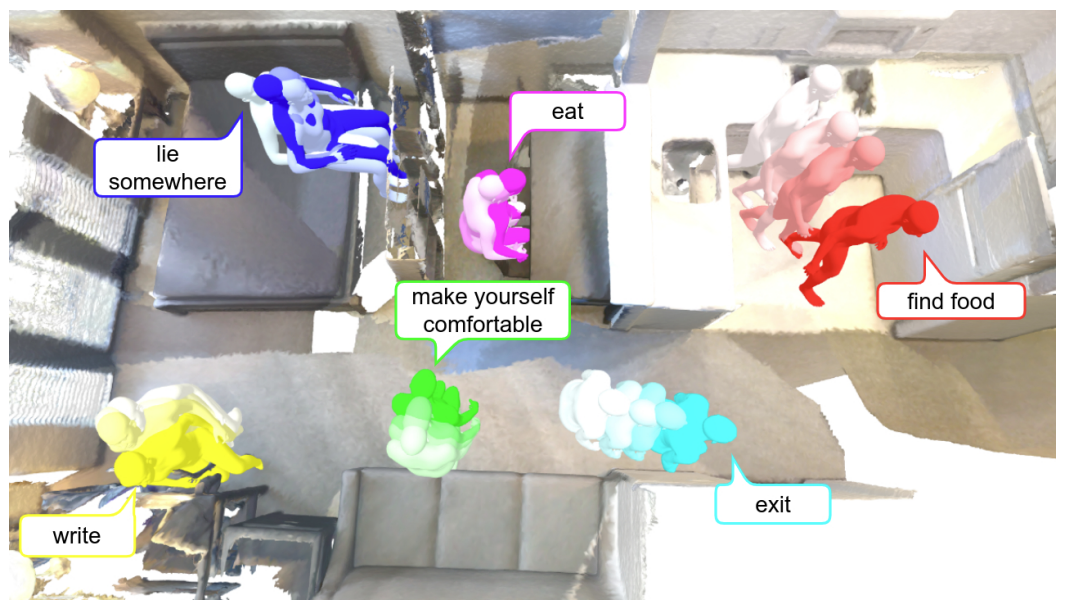
These improvements have made it easier to create more natural communication tools, allowing for precise control over how things are generated using language or even voice commands. However, methods for generating motion based on text usually ignore the surrounding 3D environment. It's important to connect these different areas to fully utilize both understanding of the scene and the accuracy of text-based commands, leading to the need for new ways to create motion.
In this paper the researchers explore how descriptions of 3D settings can be effectively linked to human movement, potentially guiding and generating contextually appropriate actions. Their approach involves two main steps. First, they pretrain the scene encoder by transferring knowledge from an existing semantic image model that utilizes an open vocabulary, ensuring a strong alignment between text and scene features. Next, they fine-tune the scene encoder for generating motions under specific conditions, employing two new strategies that enhance understanding of the category and size of the target object. To gain a comprehensive understanding of this work, click on this link to read the paper or check out their GitHub for more.