
Don't Look Twice: Speeding Up Video Transformers with Run-Length Tokenization
Equal collaboration between Carnegie Mellon University and Fujitsu Research (A sponsor of XRTC)
By Ashlyn Lacovara

An example of standard vision transformer tokens vs the tokens used by our method RLT. Video is taken from the movie Ice Age (2002).
Researchers Rohan Choudhury, Guanglei Zhu, Sihan Liu, Koichiro Niinuma, Kris M. Kitani, and László Jeni have developed a new method to accelerate video transformers by eliminating redundant tokens. This is an equal collaboration between Fujitsu Research and Carnegie Mellon University. The transformer architecture has proven extremely effective for understanding and generating text, but is harder to train and scale on videos due to their enormous size.
A common way of speeding up runtime is to prune unnecessary tokens. Current methods for token pruning encounter several limitations, including a gradual decline in training efficiency over time or reliance on a content-agnostic approach. This approach typically involves reducing the number of tokens by a constant factor, which necessitates dataset-specific adjustments to achieve optimal performance. The new approch is, RLT (Redundant Token Localization), addressing these issues by identifying and removing redundant patches before the model runs. RLT replaces redundant tokens with a single token and a positional encoding to preserve information, offering a content-aware approach with minimal overhead. RLT does not require padding examples, ensuring that reductions in tokens lead to material wall-clock speedups.
The benefits are significant: RLT increases the throughput of pre-trained video transformers by 40% with only a 0.1% accuracy drop on action recognition tasks. It also reduces training time, cutting fine-tuning wall-clock time by over 40% while maintaining baseline model performance. For video-language tasks, such as Epic Kitchens-100 multi-instance retrieval, RLT matches baseline accuracy while reducing training time and throughput by 30%.
On datasets like Kinetics-400 and Something-Something-v2, RLT reduces the total token count by 30%, and for longer videos or higher frame rates, the reduction can reach up to 80%. These improvements make RLT a powerful tool for accelerating video transformers while maintaining accuracy across various tasks.
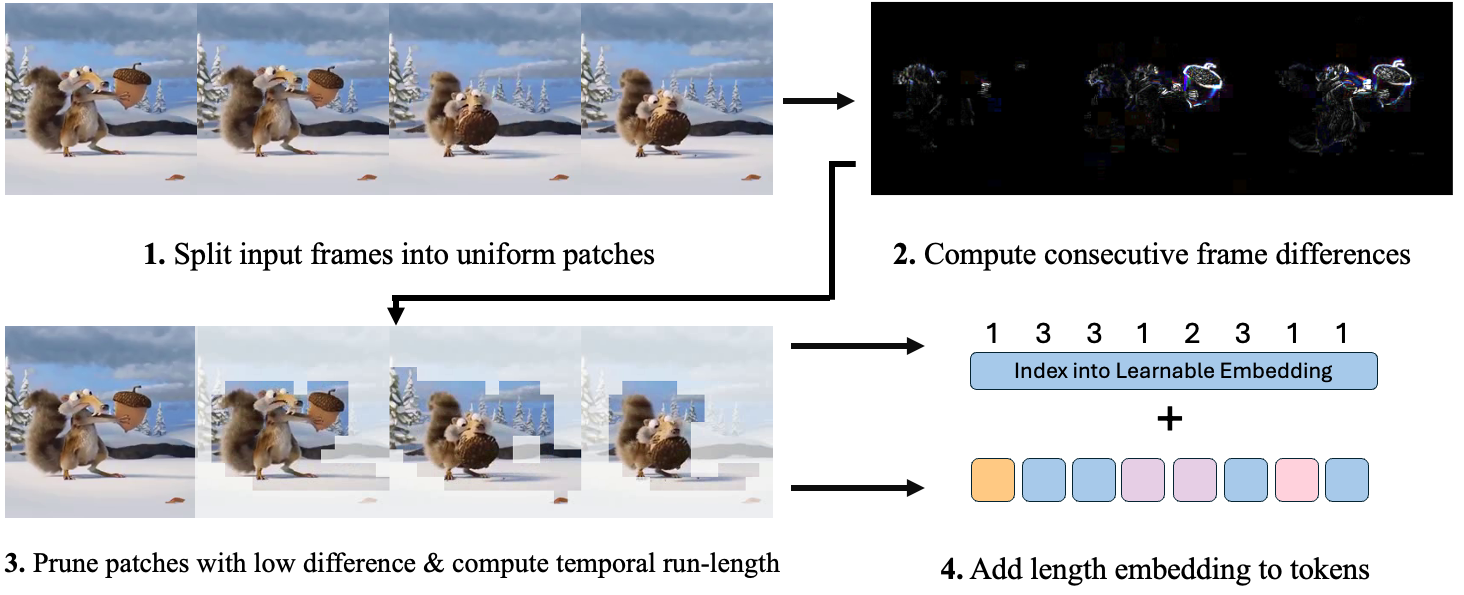
RLT identifies redundant patches by comparing input frames. Two patches are considered redundant if the mean L1 norm of their pixel differences falls below a specified threshold. For each patch in a frame, RLT compares it with the corresponding patch in the following frame, removing those that are sufficiently similar.
After pruning, RLT calculates the "run-length"—the number of consecutive redundant patches at each spatial location. This run-length, representing the token's duration, is encoded as a length embedding and passed to the transformer. The process is illustrated below with a simplified example:
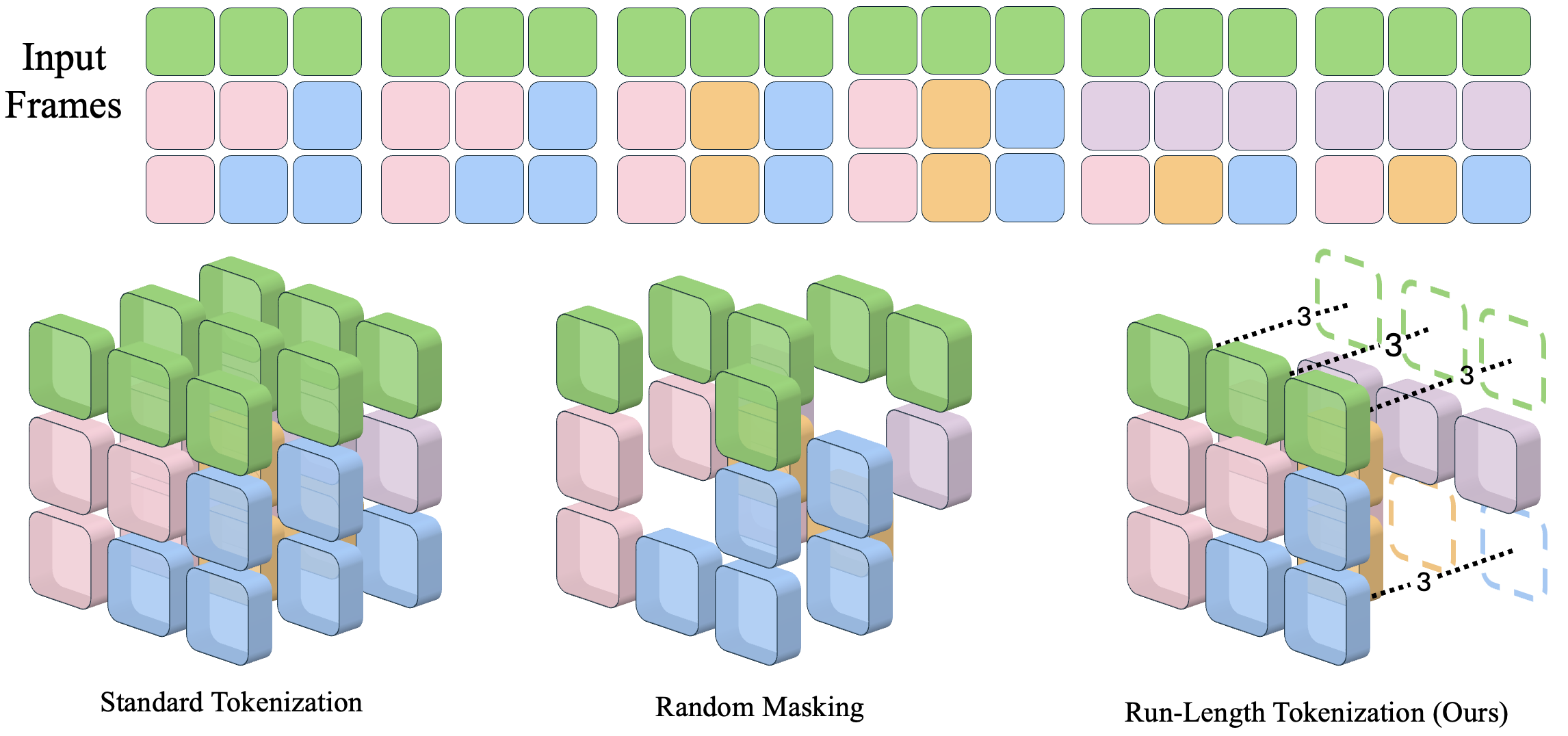
In this example, each token represents two consecutive patches at the same spatial location. Repeated tokens across frames are replaced with a single token at the start of the sequence, with their duration encoded via the length embedding. For instance, the green tokens in the top row have a duration of 3. Using this method, RLT removes 6 tokens from the input while preserving the necessary information.
A key advantage of RLT is that it determines the input's new length without running the model, eliminating the need for padding. This allows for the use of block-diagonal attention masks, enabling efficient processing of large batches with no additional overhead. By fully leveraging token reduction, RLT achieves meaningful wall-clock speedups, unlike other methods that may reduce theoretical GFLOPS but fail to deliver practical performance gains.