Neocortex Call for Proposals - Spring 2023
|
Application begins |
|
|
Application ends |
|
|
Response ends |
|
|
Allocation starts |
User access to start mid-May 2023 (rough estimate) |
The Neocortex Spring 2023 Call for Proposals (NeocortexSpring2023CFP) provides a unique opportunity to access the remarkable integrated technologies of the Cerebras CS-2 and the HPE Superdome Flex Servers available in PSC's Neocortex system. Please refer to the Neocortex Spring 2023 Call for Proposals and System Overview webinar page for details. User access is expected to begin mid-May 2023.
You can execute code on the Neocortex system by leveraging TensorFlow 2, PyTorch, the Cerebras SDK (utilizing the Cerebras Software Language, or CSL), an/or the WFA API for field equations.
How to Submit
First, identify the track that your project belongs to. Follow the EasyChair submission link above to address some general questions about your project and submit your application document in PDF format. In the application document, you are expected to address all the pertinent track-specific questions listed in the section below.
Make sure to address the corresponding track-specific questions (listed in the next section) in your application document. Failure to do so may subject your application to being rejected without review.
If you have any questions or need additional information, feel free to contact us at neocortex@psc.edu.
Tracks
- ML workflows leveraging model(s) as-is from the Cerebras Modelzoo.
- ML workflows leveraging model(s) similar to those of Cerebras Modelzoo.
- General purpose projects leveraging the Cerebras SDK.
- Domain specific programming on structured grids leveraging the specialized WFA API.
Track 1
ML workflows leveraging model(s) as-is from the Cerebras Modelzoo
This track is for researchers that intend to use at least one of the DL models as-is offered in the Cerebras Modelzoo as listed here. The models are supported via TensorFlow and PyTorch.
Cerebras modelzoo modelsSome of the ML models available in the Cerebras modelzoo are BERT (standard, classifier, name entity recognition, summarization, question answering), GPT-2, GPT-3, GPT-J, Linformer, RoBERTa, T5, Transformer, FC-MNIST, 2D Unet.
If your project falls under this category, make sure to address the following questions in your application document:
- Please, indicate which model(s) from the modelzoo do you intend to use. Do you anticipate being interested in adjusting the model architecture?
- Please, describe the dataset you are intending to use.
- How big is the dataset of interest (total dataset size, number of samples, and sample size in MB)?
- Please, elaborate on the readiness of the dataset of interest. Is it fully available at this time? If not, how soon would it be fully available?
- Please specify the shapes of the input and output tensors for your model/s.
- If possible, please specify the name of the dimensions for your input and output tensors from the previous question. E.g. (batch, input channels, height, width)
- Please specify the loss function that you would like to use.
- Please, list the libraries complementary to standard PyTorch and/or TensorFlow distributions that you would need to train your model(s).
- Please, list the key libraries that you would need for data preprocessing.
Track 2
ML workflows leveraging model(s) similar to those of Cerebras Modelzoo
This track is for researchers that intend to use DL models similar to those offered in the Cerebras Modelzoo as listed here. The models would be supported via TensorFlow and PyTorch.
The models of interest are expected to leverage mostly functionality supported by Cerebras. Please, refer to the official Cerebras documentation for more details:
Tensorflow layers supported Pytorch functionality supported
If your project falls under this category, make sure to address the following questions in your application document:
- Please, indicate which building blocks listed in Tensorflow layers supported or PyTorch functionality supported you propose to use.
- Please, attach a diagram that describes your proposed model, along the lines illustrated in this example:
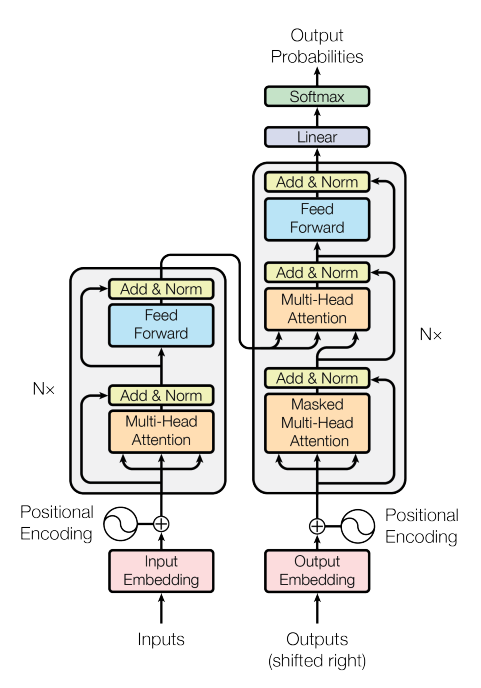
Figure: The Transformer, model architecture (Vaswani A. et. al. 2017). - How big is the model you intend to train on Neocortex? Please, describe in terms of the number of layers or kernels that comprise it. Include size in terms of MB as well.
- How big is the dataset (number of samples, MB per sample) you intend to use?
- Please specify the shapes of the input and output tensors for your model/s.
- If possible, please specify the name of the dimensions for your input and output tensors from the previous question. E.g. (batch, input channels, height, width)
- Please specify the loss function that you would like to use.
- Please, list the libraries complementary to standard PyTorch and/or TensorFlow distributions that you would need to train your model(s).
- Please, list the key libraries that you would need for data preprocessing.
Track 3
General purpose projects leveraging the Cerebras SDK
This track is for researchers that intend to leverage the Cerebras SDK to develop custom compute kernels. The SDK is for researchers who want to explore the fundamental mapping of algorithms to a gigantic rectangular mesh of independent processors with a unique memory architecture. Ongoing research work with the SDK includes a collaboration with an energy company to implement a finite difference method for seismic wave equations and implementation of Graph 500 benchmark algorithms.
Some potential research avenues of interest are the implementation of HPC benchmark algorithms, such as HPL (high performance LINPACK) and HPCG (high performance conjugate gradient), optimal mappings of sparse tensor operations, linear solvers, particle methods, or graph algorithms, for instance.
The SDK can also be used to explore the implementation of custom machine learning kernels on the CS-2. Note however, that the SDK is not currently interoperable with the CS-2's PyTorch and TensorFlow frontends, and can only be used to write standalone code. Also note that existing code written in other languages cannot be used as-is.
To better understand what leveraging the SDK entails, it can be helpful to envision what CUDA development would look like for a specific GPU architecture.
If your project falls under this category, make sure to address the following questions in your application document:
- Using the SDK requires programming in CSL, a C-like language designed specifically for the problem of massively parallel programming on the CS-2. What is your experience with HPC programming paradigms and languages, such as MPI, OpenMP, CUDA, OpenCL, etc.?
- What are the underlying computational algorithms you’re interested in exploring? What existing software packages or libraries use these algorithms?
- How is this problem bottlenecked on current hardware? Is the problem more bottlenecked by memory bandwidth, or communication costs associated with scaling up across distributed compute nodes?
- What range of problem sizes are you interested in addressing? For example, how much memory does your problem use? How does memory usage or program run time scale with problem size?
- What portion of your algorithm do you plan to port to the CS-2? Why are you interested in exploring this part of your algorithm?
- The CS-2 offers native half and single precision data types. What precision does your algorithm or use case need?
- The CS-2 is a network-attached accelerator. At a high level, the CSL programming model is similar to that of CUDA, in which data is moved between host CPU nodes and the device (CS-2) on which computational kernels are launched. How often will data need to be moved between the wafer and the worker nodes?
- Describe your general plan to map your problem onto 850,000 cores. In answering this question, it might be helpful to recall some details of the CS-2 architecture. The 850,000 cores are laid out in a mesh, with each core connected on fabric to its four nearest neighbors on the East, South, North, and West. Memory is distributed among the cores, with each core having 48 KB of local memory. 64-bit local memory reads and writes take roughly a cycle, as does sending and receiving 32-bit messages between the four neighboring cores.
Track 4
Domain specific programming on structured grids leveraging the specialized WFA API
This track is for researchers that intend to advance a project that would map to a regular grid and involve data movement patterns that are nearest-neighbor only on the grid, leveraging the WFA API (collaboratively developed by NETL and Cerebras). An example of the kind of work and performance gains achievable via the WFA API is the recent work enabling unprecedented CFD simulations.
The ideal project would involve a set of PDEs discretized to first/second order in implicit or explicit methods. The best performance gains will be with highest data intensity (or lowest algorithmic intensity). Applications could include CFD, geomechanics, electrodynamics, and some materials problems.
As you prepare your application document, it might be helpful to recall some details of the CS-2 architecture. The 850,000 cores are laid out in a mesh, with each core connected on fabric to its four nearest neighbors on the East, South, North, and West. Memory is distributed among the cores, with each core having 48 KB of local memory. 64-bit local memory reads and writes take roughly a cycle, as does sending and receiving 32-bit messages between the four neighboring cores. The memory capacity of the entire WSE is 40 GB.
If your project falls under this track, make sure to address the following questions in your application document:
- Can your problem lay out on a Hex grid (3d or many 2d parallel)?
- Does your problem involve Spatial Locality?
- Is your project Data Intense? Please, elaborate.
- Is your problem compatible with single precision and with a total data volume not exceeding 40 GB?
- Which of the following applies to your problem/project?
- Computational Fluid Dynamics (FVM, FDM, FEM, LBM)
- Structural Mechanics
- Geomechanics
- Weather/Climate
- Materials – Ising Model, Density Functional Theory
- CNN/RNN inference
- Computational Fluid Dynamics (FVM, FDM, FEM, LBM)
- Are you willing to commit to the following as you advance your project?
- Build a Python class that imports the WFA and contains a “Library” to solve your scientific problem.
- Post on a public GitHub.
Eligibility
- Projects must be non-proprietary and awardees are wholly responsible for conducting their research project activities and preparing results for publication.
- To apply, you must be a researcher or educator at a US academic or non-profit research institution.
- A principal investigator (PI) is required. The PI may not be a high school, undergraduate or graduate student; a qualified advisor must serve in this capacity in that case. Postdocs are eligible to serve as PI. Please contact us at neocortex@psc.edu if you have questions about your eligibility to apply.
For more information about Neocortex, explore the project page. For questions about this program, please email neocortex@psc.edu.
References
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. In Advances in neural information processing systems (pp. 5998-6008).