Research
Open Standards
We welcome volunteers and working group members for different Open Standards projects.
White Papers
White papers are available to sponsors.
Original Research
The patent system is highly complex and has specialized tasks, objectives, and challenges. Our research seeks to close the gap between AI capabilities and the particular needs of the patent system. Developing new language models and AI algorithms with patent-specific capabilities improves performance and productivity in the patent field.
Designing AI algorithms tailored to patent-related tasks requires expertise in both AI technology and patents. CAPA combines CMU’s world class capabilities in Artificial Intelligence, Machine Learning, and Natural Language Processing with deep expertise in patent law and patent policy. Our strength is our understanding of the special structure, knowledge, and drafting strategies that underlie the text of patents, Office Actions, PTAB decisions, and other documents. We leverage this understanding to more effectively process that text and extract subtle, useful information in ways that domain-agnostic AI techniques cannot.
Long-Term Research Agenda
Developing patent-specific AI capabilities will require significant research to overcome current limitations in the state of the art. The most daunting challenges will require the work of many research teams collectively making gradual progress over many years.
To facilitate collaboration and focus the efforts of the research community on the most salient problems, we have established a research agenda with several long-term goals. This agenda also includes short and medium term goals to help guide the progress of research over time.
This research agenda includes:
- a compilation of patent-system functions that could benefit the most from AI
- how to improve those functions with AI
- particular AI research problems that must be solved to perform those functions
- the benchmarks, data sets and other tools needed to support this research
Our research agenda consists of three broad technical objectives:
- Develop language models of patents, Office Actions, and other relevant documents
- Use the language models to create richer data sets of patent-specific information
- Use the language model and data sets to facilitate the many types of expert-level patent analysis and decision making required by industry, researchers, policy makers, and the public.
Some of our most ambitious research goals are embodied in our Patent Grand Challenge Initiative described below.
Initiatives and Projects
Our research is characterized by broad, long-term Initiatives and shorter-term Projects which contribute to fulfilling the Initiatives. Some Initiatives and Projects are described below. CAPA sponsors are also able to define additional Projects and Initiatives.
The Patent Examination Initiative
Each week over ten thousand new patent applications are filed in the US Patent & Trademark Office. AI can be used to assist Patent Examiners in their mission to deliver high quality and timely examination.
For example, AI software could assist by summarizing the salient parts of applications, highlighting key claim limitations and terms, checking term definitions, identifying enabling portions of the specification, identifying limitations that are ambiguous, illogical, or otherwise potentially problematic. A software interface specifically designed for Examiner productivity would identify and deliver the most pertinent information and analysis for robust examination.
Law Office Operations
Attorneys and staff in law offices perform many repeated actions in the course of serving their clients. Customized AI tools can increase productivity by facilitating routine but nontrivial tasks, thereby allowing attorneys to focus on higher-value activities and analysis.
Often AI can help by coordinating the results of earlier tasks in later tasks. For example, AI can automatically create memoranda summarizing the latest results from courts, administrative agencies, or opponents. AI tools can also provide outlines of cases, contracts, patent claims, and other text to quickly highlight relevant issues and evidence.
We use combinations of discriminative and generative AI techniques to provide these tools.
The Patent Grand Challenge Initiative
A field can sometimes be advanced by simply sharing the challenge of a difficult problem.
The most difficult problems in implementing patent-specific AI tools are likely too large to be solved by a small number of people in a relatively short span of time. These problems require distributed efforts over many years. If appropriately posed, such problems can also become challenges that generate interest and excitement in this new area of research, and lead to incremental progress towards extremely ambitious goals.
We are developing several Patent Grand Challenge problems. Much like the Human Genome Project or the DARPA autonomous vehicle competition, these challenges tend to focus researchers on common goals and allow a diverse set of solutions to be proposed and evaluated by the community. We hope that defining several Patent Grand Challenge problems will serve as a call-to-arms which galvanizes cross-disciplinary research in computer science, law, public policy, economics and other fields.
We are formulating Patent Grand Challenge problems around goals that are as valuable as they are difficult to accomplish. Some possible problems include:
- Given a description of a product, find all patent claims that cover that product and rank them in order of likelihood they cover that product
- Given a claim and detailed description, identify all rejections possible under 35 USC §112
- Given a description of a product and a patent, determine whether any claim of the patent covers that product
- Given a description of a product and a set of patents, rank those patents in order of likelihood that their claims cover that product
- Given a claim and corresponding detailed description, identify all patents that anticipate that claim, ranked in order of likelihood they anticipate that claim
- Describe how to manufacture a specified device using the information spread across all patents
The Patent Model Initiative
The goal of the Patent Model Initiative is to enable new types of tools that dramatically increase the productivity and accuracy of decision makers in the patent field.
A comprehensive, end-to-end model of AI patent analysis envisions several conceptual “layers” of AI text processing and information extraction for patents, as shown in Figure 1 below. Each layer includes novel data sets and tools to manipulate that data. Lower layers are responsible for directly processing the text of patents, applications, Offices Actions, PTAB opinions, and other documents via custom language models. Higher layers build upon the work of lower layers to perform more sophisticated data manipulation, analysis, and decision making.
AI algorithms can search for, aggregate, and summarize the types of information that are useful to different patent-related decisions. This initiative generates unique and valuable data sets and software tools, which in turn supports a wide range of future research projects and commercial products.
This initiative began with the design of language models, data sets, and tools at the lower layers of the model. That work helps to turn patent text into actionable information.

Figure 1: The Patent Model Initiative
Project: Defining the Foundations of AI Patent Analysis
A key research challenge is to identify the information that is necessary to AI processing of patents and related documents. The design of patent-specific AI software will benefit from answers to questions such as:
- What are the objectives in different types of patent analysis?
- What are the ways in which patents are analyzed?
- What are the decisions made and how are they currently made?
- What information is used in different types of patent analysis?
- How exactly is this information represented in the text of patents and related documents?
The answers to these questions will inform the design of future work in all layers of the Patent Model Initiative. This project will require a deep inquiry into patent law, patent practice, and actual decision making by different participants in the patent field. We expect to conduct surveys of sponsors, researchers, and others with knowledge of these issues.
Project: NLP for Patent Claims
Patent claims provide a very important type of information: the invention that is patented. Claims define both the right to exclude as well as the specific subject of numerous legal requirements for patentability. Given how important claims are to patent analysis, it will be crucial to extract different types of information from the text of patent claims. Figure 2 shows some simple information that can be extracted from an example patent claim.
Understanding the unique structure of patent claims allows software to target this information. This project leverages knowledge of claim structure to develop language models and NLP algorithms tailored to patent claims. This allows us to extract the fundamental building blocks of higher-level patent analysis.
Specific fields of technology tend to have their own terminology, relationships, and claim structure. We initially focused on patents within particular technological domains. This limited the range of possible textual forms and allowed more rapid creation of accurate software. We then expanded this project to different domains, culminating in Patent Claim NLP tools that combine both general and domain-specific claim text analysis.
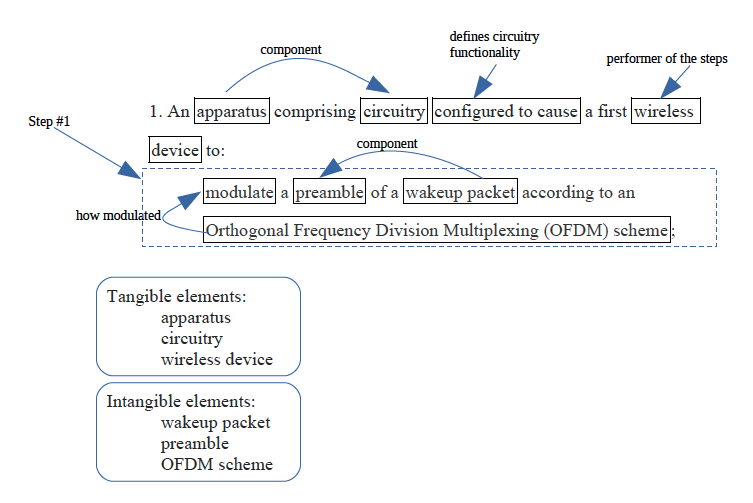
Figure 2: Patent Claim Information
Project: Extracting Data from Patent Specifications
The specifications of patents contain information that is critical to patent analysis. A specification can include definitions of claim terms, how components of a device interact, examples, alternatives, embodiments, characterizations, and boilerplate language. Much like the NLP for Patent Claims project, knowledge of the structure of patent specifications allows software to more accurately extract different types of information from text.
This project leverages knowledge of patent specifications to develop language models that identify information of interest to higher layers in the Patent Model Initiative. As in the NLP for Patent Claims project, we initially focused on patents within a particular field of technology to facilitate more rapid development.
Project: Analysis of Claim Definiteness
NLP can extract information of possible usefulness to the legal decision of claim indefiniteness. Possibly-relevant information can be found, for example, in the claim itself, in other claims, in the corresponding patent specification, or even in other patents. The NLP tool highlights for the decision maker evidence for and against the conclusion of claim indefiniteness.
Such information includes the meanings of terms in a patent claim, whether those terms are defined in the patent, whether those terms frequently occur in other patents (a sign the term is known to those in the relevant field of technology), whether the term is explained by way of examples, and whether the term is established within a set-subset relationship with other terms (e.g., a “mobile device” is defined to be a type of “computer”).
Project: Patent Citations 2.0
Patent citations analysis is used to locate relevant prior art, estimate patent value, and assess the influence of the patent. Patent citations themselves contain relatively little information: merely the identity of the previous document that the patent cites, and whether the citation was originated from the patent applicant or examiner.
AI technology can bolster the information carried by a citation. Specifically, custom NLP software can extract from various documents information related to exactly how the cited document was used during patent prosecution. Information in the text of Office Actions, applicant responses, appeal briefs and other documents can reveal whether the cited reference was used in a rejection, the type of rejection applied, and whether the rejection was overcome or maintained at various stages of prosecution. Citation analysis with this additional information provides more accurate results than conventional citation analysis.
Project: Claim Scope Evaluation
A patent claim defines exactly what the patent can exclude competitors from making, using, and selling. Automated analysis of claim scope has been stymied by the inability to go beyond basic NLP of patent claims using conventional language models and vector similarity techniques.
This project focuses on the building blocks of software tools for assessing claim scope. Various types of information extracted in CAPA’s Patent Model Initiative are used to identify features of a claim. These claim features can then be used to answer questions about claim (e.g., “does this claim utilize any chemical synthesis”), compare different claims across different metrics (e.g., “which claims refer to the greatest number of distinct devices”, “which method claim has the fewest steps”), and search the patent database for claims that contain certain concepts beyond keywords (e.g., “which claims involve an encrypted transmission between mobile device and a server with no intermediary”).