Accelerator Calculus at the Edge

The creation and use of computing accelerator chips has been a complex and controversial topic at least since the early 1980’s when I used the Intel® 8087 numeric data processor and early Texas Instruments TMS-320 digital signal processors. The decision to make or use a particular accelerator has been a hard choice across the system stack from chip makers through systems and software builders to applicatio n developers and end users. New accelerators for cryptography , video processing , graphics , speech recognition , artificial intelligence and other compute intensive workloads continually emerge. With a long personal history as a user and maker of accelerators, I have concluded:
- Where you stand depends on where you sit. A chip maker has a very different perspective than, say, a data center operator. And, two chip makers may have radically different views on the value of an accelerator depending on their current market position.
- The basic question “is it a good idea” can only be answered by “it depends”. Perhaps in a future blog, I’ll share some scars from the accelerator wars. Suffice to say there are many tradeoffs in technical approaches, business interests, market dynamics, and economies of scale. I call this the calculus of acceleration.
Edge computing changes that calculus yet again. Cloud computing strongly favors homogeneity, economies of scale and software abstraction. In a cloud data center, it may be more economical to run a workload across a hundred general purpose CPUs than fragment the fleet by creating specialty accelerator pools or deploy an accelerator card in every one of thousands of cloud servers. Conversely, edge computing favors space and performance per watt local to the user. In an edge deployment, there may be only a single server servicing a particular set of users. Applications and services may not be technically or economically feasible without the performance gains and power savings of workload-specific hardware accelerators. At the Carnegie Mellon University Living Edge Lab, we believe that many important edge-native applications like mixed reality and video analytics will require GPUs and other accelerators to achieve the performance and localized scale needed at the edge.
Up until now, I asked you to trust me on this. The accelerator debates often take place behind closed doors at different companies. Public, unbiased insight into the tradeoffs and decision factors for a real use case and a corresponding accelerator have been hard to come by. However, recently, the Living Edge Lab published “Improving Edge Elasticity via Decode Offload ”, a Carnegie Mellon University Technical Report by Ziqiang Feng, Shilpa George, Haithem Turki, Roger Iyengar, Padmanabhan Pillai, Jan Harkes, and Mahadev Satyanarayanan.
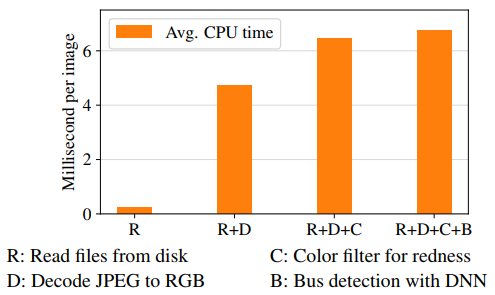
This work investigates the use of an image decoding accelerator embedded in an edge storage system used for image analytics. Edge cameras can generate massive amounts of visual data that can’t be economically stored in an uncompressed form at the edge or fully transmitted to a backend cloud. However, city-scale video analytics requires application access to decoded data from large datasets of encoded, compressed stored images or videos at the edge. As you can see in Figure 1, image decoding can be up to 70% of the analytics compute load. An accelerator that could speed up image decode at lower cost and power consumption might have merit.
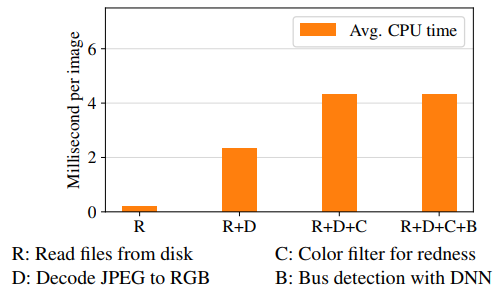
Decoding accelerators are not new; they have been embedded in CPUs, GPUs, FPGAs, and other fixed function ASICs over the years. Our report looks at whether a decode accelerator in an edge storage system, an embodiment of the computational storage concept, is “a good idea”. Figure 2 shows a roughly 40% processing time reduction using the storage-based accelerator.
To estimate the performance value of a possible decode accelerator in an edge storage system, the team built an end-to-end system emulator and used publicly available image datasets to compare the accelerator with an alternative of CPU based decode against two use cases: face recognition and detection of objects like red buses and pedestrians.

But the technical result doesn’t alone answer the “good idea” question. There are many serious considerations around software usability and portability, device sharing in multitenant edge environments, operation and management complexity for accelerator-based systems, second sourcing, future device requirements and roadmap, the size and duration of demand for that accelerator, and many other questions.
Perhaps the most valuable part of the report is its commentary on the various tradeoffs and considerations in the context of a specific use case and a specific potential product implementation, Seagate’s Kinetic HDD . It discusses the implementation of an object-based API that makes it easier for the application developer to use the accelerator without detailed knowledge of it – an important requirement for user adoption. It delves into some of the business and market issues like the need for true workload standardization (e.g., jpg encoding). It does this in the context of the edge image analytics “calculus” but has lessons for other domains as well.
I encourage you to read the report for its insights and scope whether you are a hardened veteran in the accelerator wars or would just like greater understanding of the dynamics of compute accelerators.
ACKNOWLEDGEMENTS
Our thanks to Jason Feist of Seagate for his insights and support of this work.
REFERENCE
Feng, Z., George, S., Turki, H., Iyengar, R., Pillai, P., Harkes, J., & Satyanarayanan, M. (2021). Improving Edge Elasticity via Decode Offload. Carnegie Mellon University School of Computer Science Technical Report. http://reports-archive.adm.cs.cmu.edu/anon/2021/CMU-CS-21-139.pdf