A
Quantitative Review of Associative Patterns in the Recall of Persons
Devon D. Brewer
Interdisciplinary Scientific Research
e-mail: http://www.interscientific.net/contact.html
Giovanni Rinaldi
Istituto di Analisi dei Sistemi ed Informatica del
Consiglio Nazionale delle Ricerche
Andrei Mogoutov
Ecole de Hautes Etudes en Sciences Sociales
Thomas W. Valente
This
paper was presented in the Lin Freeman Festschrift session at the 20th
International Sunbelt Social Network Conference,
ABSTRACT:
The order in which people freely recall a set of words, persons' names, or
other items indicates how they organize those items in memory. An individual's
cognitive structure of the persons with whom he or she has some particular
relation can be described by noticing how he or she associates from one person
to the next during recall. Using improved statistical measurement, we review in
detail five studies that systematically examined associative patterns in the
recall of persons and evaluate competing hypotheses about the nature of these
patterns. Individuals in these studies recalled their acquaintances, coworkers,
and friends. Across studies, the results consistently show that persons
recalled adjacently or successively are perceived to interact more with each
other than those not recalled adjacently. No other factor describes associative
patterns as well as this notion of perceived social proximity. These results,
along with related research, imply the influence of social networks on memory
for persons and suggest a universal feature of human social cognition.
The order in which people freely recall a set of words, persons' names, or other items can indicate how they organize those items in memory (Puff, 1979). Associative patterns are one important aspect of the way people recall. Associative patterns refer to the connections or relationships between adjacently recalled items. The way an individual associates from one item to the next in free recall can reveal his or her cognitive structure of those items. Associative patterns may be identified by measuring clustering in recall. Clustering of items by a particular factor occurs when successively recalled items are more likely to share some characteristic or have some relationship than items not recalled successively.
Social psychologists have proposed and tested a number of different hypotheses about associative patterns in the recall of persons. Bond and Brockett (1987) postulated that memory for acquaintances is organized on two levels. At the broader level, individuals cluster acquaintances by the social contexts in which they encounter them (e.g., school, work, family, church, etc.). That is, people should tend to list acquaintances from the same social context adjacently in recall. Within social contexts, they asserted, acquaintances are organized in memory according to personality types. In their study, Bond and Brockett (1987) observed that undergraduates clustered acquaintances moderately to strongly by social context. Within social context clusters of adjacently recalled acquaintances, however, they found that subjects clustered by personality traits only weakly.
Fiske (1995) posited that acquaintances belong to one of four relationship mode categories (communal sharing, authority ranking, equality matching, and market pricing) and that individuals cluster acquaintances in recall according to these modes. He found that adults clustered acquaintances in recall moderately by relationship mode. Both Bond and Brockett (1987) and Fiske's (1995) hypotheses are categorical. Acquaintances are assumed to belong to only one social context, personality type, or relationship mode category, and associative patterns are hypothesized to correspond to these categorical structures.
Brewer (1995b) presented a somewhat different hypothesis about the organization of persons in memory. His hypothesis is that individuals recall and think about the people whom they know primarily in social network terms. Brewer (1995b) reviewed several studies that reported results consistent with this hypothesis. Specifically, these studies suggested that perceived social proximity (or social interaction) is the principal associative factor when people recall persons whom they know. In other words, persons recalled adjacently or successively tend to interact more with each other than those not recalled adjacently. These studies showed that subjects almost uniformly display highly statistically significant clustering by perceived social proximity. However, the most relevant studies reported no information on the magnitude of clustering by social proximity at the level of individual subjects because no methods were available for computing the standard measure of clustering with respect to non-categorical structures (e.g., perceived interaction patterns). This shortcoming prevented quantitative comparisons of the degree of clustering by different variables or with the results of other studies.
The calculation of clustering by such non-categorical variables as social proximity involves a formidable computational problem. In this paper, we describe this problem and our solution to it. Then we report on reanalyses of data from two previously published studies and present results for three other studies. The last of these studies tests the social proximity, personality, and relationship mode hypotheses directly. Furthermore, we compare quantitatively the results of these studies with other studies on associative patterns in the recall of acquaintances. Finally, we evaluate the different hypotheses about associative patterns in the recall of persons based on this research and note the implications of these results on techniques for eliciting personal and social networks.
Measurement of Clustering by
Non-categorical Variables
Roenker, Thompson, and Brown (1971) introduced the Adjusted Ratio of Clustering (ARC), now the standard measure of clustering in recall by a single variable for individual subjects. The ARC equals (o - e)/(m - e), where o is the observed clustering score, e is the expected (by chance) clustering score, and m is the maximum possible clustering score for a given subject. The ARC takes a value of 1 when clustering is maximal, a value of 0 when clustering is at the level expected by chance, and negative values when clustering is less than expected. The distribution of possible clustering scores is usually not symmetric (rather, typically skewed to the right), and therefore the ARC has no universally defined lower bound.
The ARC is easily computed when the variable is binary and categorical. In this case, o is the number of adjacently recalled pairs of items that belong to the same category. The expected clustering score, e, is computed as (pw/pt) * (n - 1), where pw is the number of pairs of recalled items that are in the same category, pt is the number of all recalled pairs of items, and n is the number of items recalled. The maximum clustering score, m, is the number of items recalled minus the number of categories represented in the recalled items.
Somewhat different procedures are required to compute the ARC when measuring clustering by a variable that is not categorical. First, for a non-categorical variable, a square hypothesized associative structure matrix must be constructed that contains the hypothesized associative strengths (such as social proximities) between each pair of recalled items. These strengths may be binary or valued. (The hypothesized associative strengths for categorical variables, or category memberships, may also be represented in this matrix form, e.g., with cells for same category pairs containing "1" values and cells for all other pairs containing "0" values). In the case of a non-categorical variable, o is the sum of the hypothesized associative strengths for the adjacently recalled pairs of items. The expected clustering score, e, is the mean off-diagonal cell value (hypothesized associative strength) multiplied by the number of items recalled minus one.
The maximum clustering score, m, is much more difficult to compute for a non-categorical variable than a categorical variable. The task of computing m actually is a case of the classic Traveling Salesman Problem (TSP) (Lawler, Lenstra, Rinnooy Kan, & Schmoys, 1985). In the TSP, the goal is to find the shortest route among a set of cities (like that for a traveling salesman) such that each city is visited once and only once. The TSP typically is discussed in graph theoretic terms, with cities referred to as nodes and the distances between pairs of cities as edges. In the clustering context, the hypothesized associative structure matrix may also be conceived of as a graph, with items as nodes and hypothesized associative strengths as edges. The goal of finding the shortest Hamiltonian path (a path in which each node is visited once and only once) in the TSP corresponds to the goal of finding the maximum clustering score, once proximity data have been appropriately converted into distance data.
When the number of items recalled is few, all possible permutations of nodes (or items in a subject's recall sequence) can be enumerated and the corresponding path lengths (or clustering scores) calculated. The maximum clustering score found in this enumeration is m. When the number of nodes/items recalled is greater than 10, the enumeration approach becomes infeasible. Mathematicians and computer scientists have struggled for decades to develop algorithms to solve the TSP to optimality (Lawler et al., 1985). We used Padberg and Rinaldi's (1991) algorithm to obtain provably optimal solutions to the TSP and thus m. This algorithm produces optimal solutions even in cases with large numbers (thousands) of nodes and with non-Euclidean data on the distances between nodes.
In this paper, we compare ARCs for different variables (including categorical and non-categorical variables) and different studies, focusing on ARCs for social proximity. We define social proximity broadly to include measures of interaction- and/or sentiment-based social ties, such as social interaction, friendship, and knowing. In the studies we describe, the hypothesized associative strengths for the social proximity variables refer to the social ties between the recalled persons.
The ARCs for two variables cannot be meaningfully compared if either is categorical. An ARC for a categorical variable can be high even when clusters defined by that variable account for few adjacently recalled pairs of persons. In such a circumstance and to the extent that subjects' recalls are patterned, some other variable(s) must underlie the associations among the other pairs of adjacently recalled persons. Moreover, even though a subject may display clustering by a categorical variable, he or she may also cluster by a second variable within clusters of the first variable. To address this latter issue, when data were sufficient and available, we measured clustering by social proximity within clusters defined by a categorical variable. Such analyses control for clustering by the categorical variable. If the categorical variable is the fundamental associative factor in a subject's recall, associations within clusters defined by that category should be essentially random with respect to other variables. If subjects cluster by social proximity within clusters of a categorical variable, then it indicates that social proximity provides a fuller, more detailed description of subjects' associative patterns and suggests that clustering by the categorical variable may be a coincidental byproduct of clustering by social proximity. For these control clustering analyses, we modified Bond and Brockett's (1987) control ARC measure. For each cluster defined by a categorical variable in a subject's recall, we computed the o, e, and m clustering scores. Then we summed the observed scores together, the expected scores together, and the maximum scores together across clusters to arrive at grand o, e, and m scores for computing a control ARC. We calculated a control ARC only when the subject had at least one cluster defined by the categorical variable with four or more persons or at least two clusters defined by the categorical variable with 3 or more persons each. Appendix A shows examples of how the ARC and control ARC are calculated.
Study 1
Method
Subjects. Subjects
were 25 college-aged members of a church-affiliated Christian fellowship of
Taiwanese and Taiwanese-American young people in southern
Procedure. Subjects performed two tasks: a recall task and a pile sort of persons by social proximity. All 25 subjects did the recall task, while only 11 (5 females and 6 males) did the pile sort task. For both tasks, subjects were interviewed individually by Yang (who was a member of the fellowship), usually after fellowship meetings or church services in a private room or a quiet setting out of sight and earshot of other fellowship members. For most subjects who performed both tasks, there was a 2-3 week interval between the recall and pile sort tasks; a few subjects performed both tasks during the same interview, with the pile sort task always following the recall task.
Yang gave the following instructions orally and bilingually to subjects for the recall task:
Who are all the people involved with the [name of the fellowship]? In giving your answers, please try to give first and last names, or as much of the person's name as possible. You do not need to mention your name or my name. List aloud the names of as many people involved in the [name of the fellowship] that you can think of.
No instructions were given regarding the order in which subjects were to list names. Subjects were given 10 minutes to mention persons (all subjects finished within 9 minutes, and the mean amount of time used by subjects was 2 minutes, 25 seconds).
After 20 subjects had done the recall task, the full name (or as much as was known) of each different person mentioned in the recall interviews was written on a separate 3" x 5" note card in both English letters and Chinese characters. Cards with the names of the few persons first mentioned in the last five recall interviews were added to the set as they became available. The instructions for the unconstrained single pile sort by social proximity followed in large part those used by Freeman, Freeman, & Michaelson (1988). Subjects were first asked to separate out from the set of randomly shuffled cards those persons whom they did not recognize, i.e., could not match the name with a face. Then, subjects were instructed to sort the cards into piles of persons who tended to like, interact with, and hang around each other, both at fellowship meetings and elsewhere (see Weller & Romney, 1988, for other details on the single pile sort). Subjects' responses to this task constituted their perceptions of the social proximities among persons in the fellowship--i.e., perceptions of the fellowship's social network. Individuals' reports of social proximity in pile sort tasks have been shown to be highly accurate with respect to observed interaction patterns (Freeman, et al., 1988; Webster, 1993/1994). For brevity, perceived social proximity will be referred to here simply as "social proximity."
For the measurement of social proximity ARCs, Brewer and Yang (1994) created a social proximity matrix including all the persons recalled by subjects. Following Freeman et al. (1988), the cells in this matrix contained proportions referring to the number of subjects who placed a pair of persons in the same social proximity pile in the pile sort task divided by the number of subjects who recognized both persons. Brewer and Yang constructed a social proximity associative strength matrix for the persons recalled by each subject based on this larger social proximity matrix. Social proximity data were available for 99 of the 105 persons recalled by subjects because a few persons first mentioned in the last five recall interviews were inadvertently not included in the last few pile sort interviews. These six persons were subsequently omitted from subjects' recall sequences when computing social proximity ARCs. In addition, persons who did not actually belong to the fellowship (intrusions) and self-mentions were also omitted from subjects' recall sequences for all analyses. Observed clustering scores (o) for recall sequences with repetitions were reduced by the number of repetitions multiplied by the ((uncorrected o for sequence including repetition[s]/(number of responses [including repetitions] - 1)) (see Brewer & Yang, 1994, p. 354). We made similar corrections, as necessary, when analyzing the data from the other studies as well.
Results and Discussion
The mean number of persons recalled by subjects was 30.4 (s.d. = 10.6), out of approximately 100 persons who had attended the fellowship in the year prior to data collection. Table 1 shows the ARCs for social proximity as well as several other variables; some of the categorical ARC results were also reported by Brewer and Yang (1994). On average, ARCs for social proximity are moderate as are those for kinship relations, first name, and first letter of first name. Subjects' recalls exhibit modest clustering by sex and fellowship section (high school-aged vs. college-aged) membership.
Table
1. Summary of ARCs for Study 1
|
Variable |
n |
Mean |
Median |
S.D. |
Range |
% positive |
|
Social proximity |
25 |
.40 |
.39 |
.12 |
.05/.57 |
100 |
|
within sex clusters |
23 |
.39 |
.47 |
.27 |
-.26/.83 |
91 |
|
Kinship |
24 |
.45 |
.44 |
.29 |
-.11/1.0 |
96 |
|
Fellowship section |
17 |
.27 |
.25 |
.35 |
-.20/1.0 |
77 |
|
Sex |
25 |
.25 |
.28 |
.16 |
-.13/.58 |
96 |
|
First name |
23 |
.76 |
.84 |
.24 |
.35/1.0 |
100 |
|
First letter of first name |
25 |
.32 |
.25 |
.26 |
-.01/1.0 |
96 |
|
controlling for first name pairs |
25 |
.18 |
.06 |
.30 |
-.12/1.0 |
68 |
Subjects' clustering by social proximity remains moderate even within sex clusters. Clusters of kin related, same first name, and same first letter of first name persons are very small (typically involving only 2 or 3 persons); therefore, no control ARC analyses are possible for these categorical variables. Indeed, clusters defined by kinship and same first letter of first name account for very few adjacently recalled pairs of persons (mean = 3.3 for each variable). We performed no control analyses for social proximity clustering within fellowship section clusters either, because subjects (who were all members of the college-aged section) recalled very few high school section fellowship members. In fact, 8 subjects recalled no high school section members at all. However, Brewer and Yang (1994) reported other evidence, based on data aggregated across subjects, that social proximity clustering is still moderate within clusters of persons defined by these variables. We performed a different kind of control analysis to examine the degree of clustering by first letter of first name after controlling for clustering by first name. For this analysis, we restricted our computation of the observed and maximum scores, o and m, for clustering by first letter to those possible paths or permutations of the recall order that included the observed adjacent same first name pairs (see Brewer & Yang, 1994, pp. 358-362). The results show that the clustering by first letter is almost entirely due to clustering by first name (i.e., persons with the same first name tending to recalled adjacently), as the mean and median of the control ARCs are quite small (see Table 1).
These results indicate that social proximity is the main associative factor in subjects' recalls of fellowship members. Subjects clustered persons in recall moderately by social proximity, even within clusters of persons defined by categorical variables.
Study 2
Method
Subjects. Subjects
were 13 employees (including 11 females and 2 males) of a department in the
public affairs division of a research university in the southwestern
Procedure. Thirteen subjects participated in the study, with 10 participating in two interviews, and 3 participating in only one interview. All interviews were conducted individually and privately. The first interview (for the 10 subjects who were interviewed twice) consisted of a free recall task. Brewer (1995a) gave the following instructions orally to subjects for the free recall task:
Who are all the people who work in the [department's name] Department? Please list aloud the names of all the people who work in the [department's name] Department. You do not need to mention your name.
No instructions were given regarding the order in which subjects were to list names and subjects were allowed as much time as needed to mention all the persons they could. When subjects appeared to be done or said they had listed everyone, Brewer prompted them once by asking if there were any other persons in the department.
The second interview (for those 10 subjects who were interviewed twice) occurred 2-3 weeks after the first interview. The second interview began with a recall task. Five subjects were assigned to a free recall task (as in the first interview) and 5 were assigned to an alphabetically directed recall task (see Brewer, 1995a for details on this assignment process). For the alphabetically directed recall task, Brewer gave the same oral instructions as in the first interview, except for the second sentence, which was replaced with: "Please list aloud the names of all the people who work in the [department's name] Department in alphabetical order by their first names as best as you can."
After the recall task in the second interview, subjects performed two quasi-successive pile sort tasks (cf. Boster, 1987; Freeman, et al., 1988). The full name (or as much as was known) of each different person mentioned by subjects in the first interview was written on a separate 3" x 5" note card. (No additional persons were mentioned in the second interview). Subjects sorted persons for two different social relations: how closely persons worked with one another (work proximity) and how much persons socialized with one another (socializing proximity). The order in which subjects performed the pile sort tasks was balanced across subjects. For each pile sort task, subjects were first asked to separate out from the set of randomly shuffled cards those persons whom they did not recognize, i.e., could not match the name with a face. For the work proximity pile sort task, subjects were instructed to:
Sort these
persons into different piles according to how much they work with each other on
job-related activities. Put persons that work with one another into the same
pile.
For the socializing proximity pile sort task, subjects were instructed to:
Sort these
persons into different piles according to how much they socialize with each
other, such as going to lunch together, meeting outside of work after hours,
and/or talking with each other about things unrelated to work or the
[department's name] department. Put persons that socialize with one another
into the same pile.
After the initial sort, a subject was asked to loosen his or her criterion for working (socializing) together and, if possible, join piles of persons into larger groupings on the basis of working (socializing) together. This step was repeated with further loosening of the subject's criterion until the subject did not perceive larger groupings (other than the whole department as one pile). At this point, the cards were rearranged into the piles the subject made in the initial sort. Then the subject was asked to tighten her/his criterion for working (socializing) together and, if possible, split piles of persons into smaller groupings of persons who worked (socialized) more intensely with each other. This step was repeated until the subject did not perceive finer groupings (other than each person as a single pile).
The 3 subjects who participated in only one interview performed the free recall task and the pile sort tasks in the same session. The analysis of these subjects' recalls is presented with the other subjects' first interview recalls.
We created a work proximity associative strength matrix based on data aggregated from individual subjects' pile sort responses. To construct this matrix, we ordered the groupings of persons sorted by a subject into levels from broadest (where the subject could not join any more piles) to narrowest (where the subject could not split any pile further). The work proximity of a pair of persons from the perspective of each subject is indexed by a proportion representing the number of levels the pair was placed in the same pile divided by the total number of levels that subject used in the task. The work proximity values for each pair of persons were averaged across all subjects who recognized both persons in that pair to arrive at the aggregated matrix. We created a socializing proximity associative strength matrix in the same fashion.
Results and Discussion
Subjects recalled a mean of 16.0 persons (s.d. = 2.1) in the first interview. Table 2 presents the summary statistics on the ARCs for several variables based on data from the first interview. Many of the results for the categorical ARCs were first reported by Brewer (1995a). Location distance refers to the shortest walking distances between each of the 19 employees who had offices at the department's main location, as measured on a blueprint of the main department location. The categorical status variable refers to the five organizational status levels in the department that ranged from director to student assistants/interns.
Table
2a. Summary of ARCs for study 2, first interview
|
Variable |
n |
Mean |
Median |
SD |
Range |
% positive |
|
Work proximity |
10 |
.56 |
.58 |
.12 |
.38/.79 |
100 |
|
within status clusters |
8 |
.21 |
.31 |
.59 |
-.82/.94 |
75 |
|
Socializing proximity |
10 |
.39 |
.42 |
.10 |
.23/.52 |
100 |
|
Status |
10 |
.45 |
.48 |
.29 |
-.07/.83 |
90 |
|
Sex |
10 |
.06 |
.15 |
.22 |
-.24/.28 |
60 |
|
First letter of first name |
10 |
.08 |
.07 |
.20 |
-.24/.43 |
70 |
|
Location distance |
|
|
|
|
|
|
|
Non-locationally oriented Ss |
10 |
.25 |
.22 |
.13 |
.11/.54 |
100 |
|
Locationally oriented Ss |
3 |
.63 |
.65 |
.04 |
.58/.67 |
100 |
Brewer (1995a) observed that three subjects' recalls are clearly locationally oriented as revealed by their spontaneous comments and inspection of their recall sequences. All summaries in Table 2 except for the location distance ARCs exclude these subjects. Subjects clustered fellow employees in recall by work proximity moderately strongly. For these subjects, clustering by socializing proximity and status are moderate. Clustering by sex and first letter of first name tend to be very slight to negligible. The non-locationally oriented subjects clustered modestly by location distance.
Clustering by work proximity within status clusters is somewhat weaker than work proximity clustering overall, yet still noteworthy. In analyses based on data aggregated across the non-locationally oriented subjects, Brewer (1995a) demonstrated that once clustering by location distance is controlled, clustering by work proximity still is present, while clustering by location distance essentially disappears once clustering by work proximity is controlled. The mean work proximity ARC is much higher than the mean location distance ARC (paired t = 6.07, df = 9, p < .001), and all (10/10) non-locationally oriented subjects had a higher ARC for work proximity than for location distance. Similarly, the mean work proximity ARC is substantially higher than the mean socializing proximity ARC (paired t = 2.73, df = 9, p < .05), and 8 of 10 non-locationally oriented subjects had a higher ARC for work proximity than for socializing proximity. Also, ethnographic evidence suggests that work relationships were more important than socializing relationships in shaping how subjects perceived each other (Brewer, 1995a). Therefore, we conclude that socializing proximity and location distance are not fundamental associative factors apart from their relationships to work proximity. These results indicate that, of the variables examined, work proximity appears to be the most general and primary associative factor.
The three locationally oriented subjects clustered by location distance moderately strongly. Their location distance ARCs provide an interesting comparison to the work proximity ARCs for the other subjects. The locationally oriented subjects consciously recalled their fellow employees in a locationally oriented manner. The mean location distance ARC for the locationally oriented subjects approximates the mean work proximity ARC for the non-locationally oriented subjects. This suggests that it is unlikely there is another variable conceptually and empirically distinct from work proximity that provides a better description of the non-locationally oriented subjects' associative patterns. It also suggests that this level of clustering may be close to the maximum level of clustering by any variable that might be observed in an empirical setting like this department, because the level of clustering observed in a subject's recall is likely to be highest when the associative strategy is deliberate and based on a concrete referent (as it was for the locationally oriented subjects).
The free recall subjects in the second interview had similar ARC results as subjects in the first interview (see Table 2b). The ARC results for the alphabetically directed subjects in the second interview parallel those for subjects in the first interview except that the magnitude of their ARCs for most variables is slightly lower and the degree of first letter of first name clustering is notably higher (see Table 2c). This indicates that subjects' natural associative tendencies are still evident even when they attempt to recall persons using a systematic and familiar strategy for organizing names.
Table
2b. Summary of ARCs for study 2, second interview, free recall subjects
|
Variable |
n |
Mean/Median |
Range |
|
Work proximity |
2 |
.64 |
.55/.73 |
|
within status clusters |
1 |
-.29 |
-.29/-.29 |
|
Socializing proximity |
2 |
.60 |
.57/.63 |
|
Status |
2 |
.24 |
.24/.24 |
|
Sex |
2 |
.12 |
-.24/.48 |
|
First letter of first name |
2 |
-.18 |
-.19/-.17 |
|
Location distance |
|
|
|
|
Non-locationally oriented Ss |
2 |
.42 |
.31/.53 |
|
Locationally oriented Ss |
3 |
.57/.66 |
.32/.72 |
Table 2c. Summary of ARCs
for study 2, second interview, alphabetically directed subjects
|
Variable |
n |
Mean |
Median |
SD |
Range |
% positive |
|
Work proximity |
5 |
.39 |
.40 |
.25 |
-.03/.69 |
80 |
|
within status clusters |
3 |
1.0 |
1.0 |
.00 |
1.0/1.0 |
100 |
|
Socializing proximity |
5 |
.20 |
.24 |
.26 |
-.13/.61 |
60 |
|
Status |
5 |
.19 |
.12 |
.17 |
.02/.42 |
100 |
|
Sex |
5 |
.11 |
.21 |
.23 |
-.19/.35 |
60 |
|
First letter of first name |
5 |
.38 |
.38 |
.35 |
-.16/.70 |
80 |
|
Location distance |
|
|
|
|
|
|
|
Non-locationally oriented Ss |
5 |
.19 |
.21 |
.18 |
-.12/.37 |
80 |
Study 3
Method
Subjects. Eleven
Russians who immigrated to
Procedure. Each subject was first asked to name aloud members of his or her personal network ("circle of relationships"). They were allowed to mention as many persons as they wanted and were given no instructions on the order in which to recall persons. Later in the interview, subjects were asked to indicate which other network members each network member knew by referring to a written list of network members. Subjects were also asked to provide information about the individual characteristics of their personal network members (sex, profession, country of current residence, age, and ethnicity/nationality) and the relationships with their network members (including, among other characteristics, duration of relationship and language of communication).
Two subjects were interviewed three times over several years. For one of these subjects, only data from the first interview are included in our analysis. For the other subject, only data from the third interview are included in our analysis because the data from the first two interviews are incomplete. Six subjects recalled one or more (range = 1 to 3) couples (e.g., parents, or another husband-wife couple) as a single response. We omitted these couples from analysis because these responses do not refer to individual persons.
The raw knowing data for each subject are nonsymmetric, most likely due to subjects' lapses of attention in responding. Because the knowing relation is by definition symmetric (or virtually symmetric), we symmetrized each subject's knowing associative structure matrix (where 1 = pair knows each other, and 0 = otherwise). Subjects' descriptions of their network members yielded easily classifiable information on seven categorical variables: sex (female/male), country/region of current residence (Russia / France / USA / Germany / Latvia / Israel / Belgium / Africa), age (10 year categories; 0-9 / 10-19 / 20-29, etc.), ethnicity / nationality (Russian / French / Chinese / Latvian / Japanese / Ukranian / Russian-French / Polish-French / Armenian / USA / Italian / Belgian / Polish / Jewish), duration of relationship (0-12 months / 13-60 months / 61-120 months / 121+ months), language of communication (Russian / French / English), and first letter of name (French spelling; each letter of the French alphabet). Network members with missing data on a particular variable were deleted from that subject's recall sequence for analysis on that variable.
Results and Discussion
Subjects recalled a mean of 22.0 personal network members (s.d. = 10, range = 10 to 41). Table 3 presents the ARCs for this study. On average, subjects showed virtually no tendency to cluster network members in recall by sex or first letter of name, and only a slight tendency to cluster by age. However, subjects displayed mild to moderate clustering by duration, language, ethnicity, and country of residence. The control ARC results indicate that clustering by knowing persists undiminished within clusters defined by these variables (we did not conduct control analyses with respect to language becuase it corresponded closely to ethnicity). Therefore, knowing appears to be the fundamental associative factor for these subjects. In addition, the couples who were recalled as "single" network members (and were omitted from our analyses) provide further evidence for association by knowing.
Table
3. Summary of ARCs for study 3
|
Variable |
n |
Mean |
Median |
SD |
Range |
% positive |
|
Knowing |
11 |
.34 |
.29 |
.22 |
.00/.73 |
91 |
|
within duration clusters |
5 |
.43 |
.27 |
.55 |
-.25/1.0 |
80 |
|
within ethnicity clusters |
10 |
.30 |
.38 |
.65 |
-1.0/1.0 |
70 |
|
within country clusters |
11 |
.36 |
.43 |
.34 |
-.25/1.0 |
82 |
|
Duration |
10 |
.25 |
.22 |
.24 |
-.14/.55 |
90 |
|
Language |
8 |
.37 |
.52 |
.41 |
-.26/.77 |
75 |
|
First letter of name |
11 |
-.04 |
.03 |
.16 |
-.25/.23 |
54 |
|
Sex |
11 |
-.03 |
-.17 |
.41 |
-.45/1.0 |
36 |
|
Age |
11 |
.23 |
.13 |
.26 |
-.25/.56 |
82 |
|
Ethnicity |
10 |
.36 |
.42 |
.32 |
-.15/.83 |
80 |
|
Country of residence |
10 |
.55 |
.47 |
.31 |
.07/1.0 |
100 |
The broad and moderately strong clustering by country of current residence probably reflects association by country in which the subject interacted with personal network members. This pattern is most likely a consequence of immigration. Country of residence is unlikely to be a major associative factor for people who are not immigrants because their personal network members will not vary much in terms of their country of current residence.
Study 4
Method
Subjects. In the
course of evaluating the Baltimore (U.S.A.) needle exchange program, Valente
and Vlahov (2001) collected data on program participants' personal networks.
The program was designed to prevent the spread of HIV and other infections by
distributing new, sterilized needles to drug injectors in exchange for their
used needles. Since the beginning of the evaluation in 1995, thousands of drug
injectors have participated in the needle exchange, and some of them have also
been interviewed for the in-depth part of the evaluation. For our analysis, we
considered only those 205 participants who were first interviewed for the
evaluation between
The mean age for these 59 subjects was 37.2 years (s.d. = 10.1) and 77 percent were male. Eighty-eight percent were black, 7 percent were white, and 5 percent were of some other race. Ninety-six percent of the subjects were unemployed, and only 53% had graduated from high school or earned a general equivalency degree. Subjects had been injecting drugs for a mean of 14.4 years (s.d. = 12.0)
Procedure. One section of the interview for the evaluation focused on personal networks. Interviewers asked subjects the following network elicitation question:
Now I'm going to ask you about some of the people you hang out with, and some of the people with whom you might inject drugs. I will not ask you for any names--only initials. Can you please give me the initials of up to five of your closest friends?
If the subject needed clarification or prompting, interviewers said "by 'friends,' I mean the people you spend time with on a regular basis." Interviewers gave no instructions on the order in which friends were to be listed. Subjects responded orally. The interviewer recorded no more than five friends' initials. After eliciting the initials of a subject's friends, the interviewer asked several questions about the behaviors the subject and each friend had engaged in together (e.g., sharing syringes, drinking alcoholic beverages, etc.). The interviewer then asked the subject the following questions about the ties between the friends:
Now I'm going
to ask you if some of these friends know each other. [For each unordered pair
of friends] Do [one friend's initials] and [another friend's initials] know
each other?
Subjects could give "yes," "no," or "don't know" responses. "Don't know" responses were coded as 'no' responses because the subject apparently perceived no tie between the pair (Brewer, 1997, used the same coding rule).
Results and Discussion
The 59 subjects included in the analysis met two measurement criteria: 1) they recalled 4 or 5 friends, and 2) there was at least some variation in the knowing ties between their friends. ARC scores based on 3 or fewer friends are not meaningful, as there are only 3 different orders (and their mirror images) in which 3 friends may be recalled. Also, if there is no variation in the ties between friends (that is, if the subject reports that each pair of friends knows each other or that each pair doesn't know each other), no ARC can be computed, because o, e, and m are all equal.
Overall, subjects tended to cluster friends in recall according to which friends know each other. For the 59 subjects, the mean ARC is .19 and the median ARC is .17. The range of ARCs is -1.5 to 1.0 and the standard deviation of ARCs is .75; two subjects' ARCs were less than -1.0. Sixty-one percent of subjects' ARCs are positive, and 36% had maximum ARCs of 1.0. Although these subjects' ARCs are lower on average than those observed in the other studies, recall was truncated for many subjects (because of the 5 friend limit). Furthermore, recall sequences of only 4 or 5 persons produce much more erratic ARCs than longer sequences because each adjacently recalled pair has a relatively large influence on the score obtained (a phenomenon analogous to having large sampling variability as a result of small samples).
Study 5
Method
Subjects. Subjects
were 25 undergraduate students (17 females and 8 males) who participated in a
class exercise in a social psychology course taught by the first author at the
Procedure. Subjects responded to questions in a self-administered questionnaire. The first page of the questionnaire asked subjects to identify a particular social community in which they had been involved. The instructions were:
Think of a social group or community in which you are currently involved or have been involved in the past. This group should be a set of 10 or more people who have or had regular face-to-face interaction with each other. The group could be members of a church; employees who work in a particular office, department, or company; students in an elementary, middle, or high school; members of a formal or informal social group (such as a club); or some other community of persons tied together by regular social interaction.
Once subjects had identified an appropriate community, they answered questions about the type of community and the duration and recency of their involvement in the community, and then waited for further instructions.
After all subjects had completed the questionnaire to this point, subjects then responded to the person elicitation question presented visually on an overhead projector and orally by the first author. This question asked subjects to:
Please write
down the names of 10 persons whom you know in this group. Write the names down
in the order they occur to you, with the first one going in the first blank, the
second one in the second blank, and so on. Please do not use persons' full
names--just write down first names and/or whatever else is required to
distinguish them from each other.
When subjects finished writing names down, they answered a series of questions about these persons. For the first set, subjects reported how similar in personality they perceived each unordered pair of persons to be on a scale from 1 to 10, with 1 meaning 'not similar at all' and 10 meaning 'extremely similar.' This approach to measuring perceived similarity in personality represents an improvement over Bond and Brockett's (1987) approach of having subjects assign each acquaintance to a single personality trait category only. Our pairwise ratings capture the multidimensional, continuous variation in personality, while categorical assignments do not.
For the second set of questions, subjects reported their perceptions of the social proximity for each unordered pair of persons. The instructions for these questions asked subjects to 'rate how much each pair of persons interacts/interacted with each other overall, both in the context of the group and outside of the group. Rate how much each pair of persons interacts/interacted on a scale from 1 to 10, with 1 meaning 'not at all' and 10 meaning 'always.'' For both the personality similarity and social proximity judgments, subjects put their ratings in the cells of a lower half matrix, with the order of persons' rows and columns corresponding to their order of output in the recall task.
For the third set of questions, subjects indicated how close their relationships were with each person recalled on a scale from 1 to 10, with 1 meaning 'not close at all' and 10 meaning 'extremely close.' Other questions in this section asked about each person's role relationship to the subject and role in the group. For the fourth set of questions, subjects classified each person recalled into one of Fiske's four relationship mode categories (communal sharing, authority ranking, equality matching, and market pricing). Subjects read Fiske's written descriptions of the four models (provided by Alan Page Fiske; see Appendix B) before making their classifications. The final section of the questionnaire included questions about the subject's demographic characteristics.
Results and Discussion
Thirty-two percent of the communities subjects identified were religiously oriented, 28% were work-related, another 32% were broadly 'social' (e.g., clubs), and the rest were residential or school-based communities. Sixty-four percent of subjects were currently involved in the communities they identified. For those not currently involved in their particular community, their last involvement was a mean of 38 months prior to the interview. Overall, subjects had been involved with their communities for 39 months on average (there were no meaningful differences in duration of involvement between those currently involved and those no longer involved in their communities).
Twenty-one subjects each recalled 10 persons, and the other four each recalled 8 or 9 persons. Table 4 shows the summary statistics for the ARCs. For these analyses, we treated the social proximity and personality data as interval scale measurements. Subjects clustered persons in recall mildly to moderately by perceived social proximity, perceived similarity of personality, and relationship mode. Two subjects recalled persons who did not vary in terms of relationship mode (i.e., they classified all recalled persons into just one relationship mode category). Therefore, for these subjects, relationship mode was by definition irrelevant to associative patterns.
Table
4. Summary of ARCs for study 5
|
Variable |
n |
Mean |
Median |
S.D. |
Range |
% positive |
|
Subjects' actual recalls |
|
|
|
|
|
|
|
Social proximity |
25 |
.33 |
.35 |
.30 |
-.48/.88 |
88 |
|
within relationship mode clusters |
20 |
.42 |
.45 |
.49 |
-.67/1.00 |
85 |
|
Personality |
25 |
.20 |
.26 |
.25 |
-.28/.56 |
76 |
|
Relationship mode |
23 |
.44 |
.50 |
.42 |
-.35/1.00 |
87 |
|
Social proximity-based simulated recalls |
||||||
|
Personality |
25 |
.14 |
.12 |
.09 |
.02/.34 |
100 |
|
Relationship mode |
23 |
.09 |
.05 |
.15 |
-.16/.44 |
61 |
|
Closeness-oriented simulated recalls |
||||||
|
Social proximity |
23 |
-.08 |
.03 |
.30 |
-1.01/.15 |
65 |
|
Personality |
23 |
-.06 |
-.01 |
.24 |
-.96/.17 |
48 |
|
Relationship mode |
23 |
.15 |
.11 |
.26 |
-.23/.71 |
65 |
Subjects' clustering by social proximity remained moderate even within relationship mode clusters. This indicates that social proximity was a more basic and general associative factor than relationship mode. In addition to the 2 subjects who recalled persons from just one relationship mode category, 3 other subjects did not have large enough relationship mode clusters to permit control analyses.
The mean social proximity ARC is higher than the mean personality ARC (paired t = 2.81, df = 24, p < .01), and 72% (18/25) of subjects had a higher ARC for social proximity than for personality. These findings demonstrate that social proximity describes subjects' associative patterns better than similarity in personality.
The apparent clustering by personality appears to be a
consequence of the more fundamental clustering by social proximity and the
similarity of the social proximity and personality associative structure
matrices for the persons recalled by individual subjects. We simulated recall
sequences (paths) for each subject with a model based on the social proximities
among the persons he or she recalled to examine how associating by social
proximity might incidentally produce clustering by other variables. In this
model (cf. Romney, Brewer, and Batchelder, 1993), recall paths are generated
probabilistically such that the first person recalled is chosen at random and
then successive persons are 'recalled' proportional to the social proximities
between the most recently recalled person and persons not yet recalled. In this
latter process, the probability that a person j will be recalled next in the sequence can be defined formally as
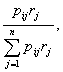 where i refers to the person most recently
recalled, pij represents
the social proximity between person i
and j, and rj indicates whether a person has already been recalled
(0 if already recalled, 1 otherwise). This process is Markovian because the
probability of any person being recalled next is independent of the order of
persons recalled previously. The sampling process is also without replacement
because a person could be recalled only once.
where i refers to the person most recently
recalled, pij represents
the social proximity between person i
and j, and rj indicates whether a person has already been recalled
(0 if already recalled, 1 otherwise). This process is Markovian because the
probability of any person being recalled next is independent of the order of
persons recalled previously. The sampling process is also without replacement
because a person could be recalled only once.
We simulated 1,000 paths for each subject based on the social proximities among the persons he or she recalled and then compared the mean simulated path length with the subject's expected and maximum clustering score for a variable. When we used raw social proximities in this model, the simulated paths showed less clustering by social proximity than in subjects' observed paths. By transforming the proximities (i.e., raising them to 1.3rd power), we produced simulated paths with social proximity ARCs that closely resembled subjects' observed social proximity clustering in the aggregate (simulated paths: mean and median = .33, range = .09 to .52; observed paths: mean = .33, median = .35, range = -.48 to .88). These social proximity-based simulated paths show nearly as much clustering by personality as subjects' actual recalls do (see Table 4). Thus, modest clustering by similarity in personality would be expected even when subjects primarily associated in recall according to social proximity.
The apparent clustering by relationship mode also is likely a byproduct of clustering by social proximity and serial order recall patterns. Serial order patterns refer to which persons or types of persons tend to be recalled earlier or later in recall. Research has consistently shown that persons with whom subjects have strong social ties and who are of high status (in the community from which a subject recalls persons) tend to be recalled earlier than other persons (Brewer, 1995b). In one study these two serial order patterns were mostly independent (Brewer, 1995a). The data from this study reinforce these results. Across the 25 subjects, the mean unweighted Pearson correlation (Rosenthal, 1991) between output serial position and a relationship closeness is -.53 (median = -.52, range = -.97 to .29). In addition, 14 subjects listed a role for one of the persons they recalled that unambiguously corresponded to the highest status in the community. It was impossible to ascertain the relative status of other persons--aside from being less than the highest status persons--objectively from the available data. For 10 of the 14 subjects, the highest status person was recalled first; only one subject recalled the highest status person in the second half of recall. However, subjects reported only typical levels of relationship closeness with the highest status persons: only 4 of the 14 highest status persons had the highest level of closeness, and 7 had closeness values at or below the median for the persons recalled by a subject.
Conceptually, three of the four relationship mode categories
seem to form a rank order of relationship closeness (communal sharing >
equality matching > market pricing; see Appendix B). Empirically, this
ranking and relationship closeness are strongly related. For the 19 subjects
who recalled persons falling in two or more of these relationship mode
categories, the mean gamma correlation is .82 (median = 1.00, range = .00 to
1.00). (The fourth relationship mode category, 'authority ranking', has no
obvious interpretation for relationship closeness. On average, 22% of the
persons recalled by a subject were in the 'authority ranking' category; six
subjects did not assign any of the persons they recalled to this relationship
mode category.)
We simulated recall paths based on a relationship
closeness-oriented serial order process to assess the contribution of such a
pattern toward clustering by relationship mode. In this model, recall paths are
generated probabilistically such that the first and successive persons recalled
are 'recalled' proportional to the relationship closeness values of the persons
not yet recalled (cf. Brewer and Yang, 1994; Brewer, 1995a). The probability
that a person i will be recalled next
in the sequence is
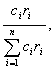 where ci refers to a
person i's closeness value and ri indicates
whether a person i has already been
recalled (0 if already recalled, 1 otherwise). As with the social
proximity-based simulation model, the sampling process is Markovian and without
replacement. We simulated 10 sequences for each subject who had a relationship
mode ARC. These simulated sequences resembled, on average, the observed Pearson
correlation between persons' output serial positions and relationship closeness
values in that subject's actual recall. By raising the closeness values, ci, to varying powers, we
generated sequences that had a median output serial position -- relationship
closeness correlation within |.09| of a subject's observed correlation.
where ci refers to a
person i's closeness value and ri indicates
whether a person i has already been
recalled (0 if already recalled, 1 otherwise). As with the social
proximity-based simulation model, the sampling process is Markovian and without
replacement. We simulated 10 sequences for each subject who had a relationship
mode ARC. These simulated sequences resembled, on average, the observed Pearson
correlation between persons' output serial positions and relationship closeness
values in that subject's actual recall. By raising the closeness values, ci, to varying powers, we
generated sequences that had a median output serial position -- relationship
closeness correlation within |.09| of a subject's observed correlation.
The relationship closeness-oriented simulated paths displayed modest clustering by relationship mode (see Table 4). The closeness-oriented simulated paths showed no tendency, however, toward clustering by social proximity or personality. The social proximity-based simulated paths described earlier exhibited slight but nontrivial clustering by relationship mode. It would seem that the closeness-oriented serial order pattern and social proximity-based associations have independent and additive contributions toward the clustering by relationship mode in subjects' actual recalls (means of relationship mode ARCs from the two simulation processes = .15 + .09 = .24 vs. mean relationship mode ARC in subjects' actual recalls = .44). Another part of the clustering by relationship mode observed in subjects' actual recalls is likely accounted for by a status-oriented serial order recall process, because persons of similar status (above or below the subject's own) would likely constitute 'authority ranking' clusters. The simulation results, then, suggest that most of the apparent clustering by relationship mode can be explained by recall processes that do not involve associations by relationship mode specifically.
This study provides the strongest evaluation to date of the competing hypotheses about associative patterns in the recall of persons. Subjects recalled persons from a wide variety of communities. The results clearly point to perceived social proximity as the primary and most general associative factor and also indicate why apparent clustering by personality and relationship mode can be observed even when these variables may not be the actual or underlying associative factor.
General Discussion
Of the variables examined, social proximity provides the best account of associative patterns in the recall of persons in each of these five studies. Overall, subjects clustered persons in recall moderately by social proximity, and clustering by social proximity was undiminished within clusters defined by several different categorical variables. Table 5 summarizes each study's social proximity ARC results. The results in the table suggest that more precise measurement of social ties, especially that gained through judgments of social proximity aggregated across subjects, may permit higher levels of clustering by social proximity to be observed.
Table
5. Overview of ARCs for Social Structural Variables in Person Recall Studies
|
Study |
Variable |
Data type |
n |
Mean ARC |
|
1 |
Social proximity |
Single pile sort data aggregated across 11 subjects |
25 |
.40 |
|
2 |
Work proximity |
Quasi-successive pile sort data aggregated across 10 subjects |
10 |
.56 |
|
3 |
Knowing |
Dichotomous ties (know/don't know) for individual subjects |
11 |
.34 |
|
4 |
Knowing |
Dichotomous ties (know/don't know) for individual subjects |
59 |
.19 |
|
5 |
Social proximity |
10 pt. rating scale for ties for individual subjects |
25 |
.33 |
|
Bond et al. (1985) |
Social context |
Dichotomous/categorical for individual subjects |
18 |
.60 |
|
Bond et al. (1987) |
Social context |
Dichotomous/categorical for individual subjects |
21 |
.72 |
|
Fiske (1995) |
Social context |
Dichotomous/categorical for individual subjects |
51 |
.44 |
|
Brewer et al. (2002) |
Social proximity |
Dichotomous for individual subjects -- sex partners |
24 |
.27 |
|
Brewer et al. (2002) |
Social proximity |
Dichotomous for individual subjects -- injection partners |
33 |
.27 |
Interestingly, the magnitude of clustering by social proximity and related variables in these studies is very similar to that of semantic clustering when people free list items from semantic domains. When people recall words belonging to particular semantic domains (such as types of fish or kinds of furniture), they cluster them according to the semantic similarity of the words. Brewer, Garrett, and Rinaldi (2002a) measured semantic clustering in adults' free lists of types of fruits and recreational/street drugs. The mean ARC is .44 (median = .49) for fruits and .26 (median = .40) for drugs. Given the probabilistic nature of associative recall processes (cf. Romney, Brewer, & Batchelder, 1993), these levels of clustering for a primary associative factor may be about as high as one can expect to observe in typical, natural settings.
Table 5 also shows the mean ARCs for clustering by social context reported by Bond, Jones, and Weintraub (1985), Bond and Brockett (1987), and Fiske (1995). Social context may be considered a close cousin of social proximity since persons in the same social context tend to know and interact more with each other than persons who do not share a social context. Indeed, clustering by social context may actually reflect clustering by social proximity. It is also possible that focusing on one particular social context at a time in recall serves to anchor and delimit separate sections of one's personal network that may be searched more easily and efficiently (cf. Williams & Hollan, 1981) than one's whole personal network at once. Subjects in all three of these studies recalled acquaintances, a broader class of persons than the sets of persons recalled by subjects in our five studies. (Subjects in studies 1, 2, and 5 recalled persons from a single social context, or community, only). These researchers observed moderate to strong categorical clustering by social context, which is consistent with the first part of Bond & Brockett's (1987) hypothesis. However, Bond and Brockett's (1987) subjects clustered acquaintances by personality traits within social context clusters only weakly (mean control ARC = .14).
Fiske (1995) reported mean ARCs for other variables, including relationship mode (mean ARC = .28). Of all the variables he examined, the highest mean ARC is for social context. However, there is no way to assess which of the variables Fiske studied provides the best description of associative patterns, because he did not conduct any control analyses.
The results from Brewer, Garrett, and Rinaldi's (2002b) study of patterns in the recall of sexual and drug injection partners are the last shown in Table 5. Subjects in this study clustered their partners by social proximity to a substantial degree, but they also clustered moderately by other, categorical variables (e.g., role relationships and locations of interaction with partners, both of which may be related to social context). Brewer et al. (2002b) did not perform control analyses because the role relationship and location clusters were too small. However, the temporal patterns in subjects' recalls suggested that social proximity may have been the primary associative factor. The inter-response times for adjacently recalled pairs of partners correlated more strongly with pairs of partners' social proximities than pairs' similarities on the other variables.
Brewer (1995b) reviewed other evidence for social proximity as the primary associative factor in the recall of persons, the most relevant of which we recapitulate here. Williams and Hollan's (1981) qualitative observations of four adults' recalls of their high school classmates suggested prominent clustering in recall by friendship, kinship, and group affiliation. Furthermore, as in the Brewer et al. (2002b) study, subjects' inter-response times for adjacently recalled pairs of persons correlated moderately to moderately strongly with social proximity in studies 1 and 2 (Brewer & Yang, 1994; Brewer, 1995a). This indicates that pauses between successively recalled persons tended to be shorter for socially close pairs than socially more distant pairs. See Brewer (1995b) for a summary of additional research on the role of social proximity in other aspects of social cognition.
Associative processes may be the primary influence on how people recall, such that successive recalls are determined mainly by the social ties between persons. Even concerted efforts by subjects to recall persons in a particular order may not be very successful if that order does not correspond to subjects' underlying cognitive structure of those persons (Brewer, 1995a). The consistency of clustering by social proximity across studies is remarkable and suggests a universal feature of human social cognition. Further cross-cultural and developmental studies are required, though, to test this assertion more thoroughly. Another task for future research is to model associative and serial order processes simultaneously to produce simulated recalls that mirror both types of patterns found in subjects' observed recalls.
The role of social proximity as the fundamental associative factor in the recall of persons can be explained in terms of both proximate mechanisms and ultimate evolutionary principles (Daly & Wilson, 1983). The most plausible proximate mechanisms are classic associative learning processes. In this view, associative links between items (persons in this case) are built up in memory proportional to their degree of spatiotemporal contiguity. Thus, persons often seen interacting together and mentioned together in everyday conversation therefore become more strongly associated in memory than persons not seen together or mentioned together in everyday conversation (Bond et al., 1985).
From an evolutionary perspective, knowledge of others'
affiliation (social proximity) patterns is adaptive given the influence of such
patterns on survival, reproduction, and countless other outcomes. The adaptive
value of such knowledge would likely be especially great in the environments in
which humans evolved--hunting and gathering societies where nearly all social
interactions were within relatively small communities of individuals (
Our results also suggest that one key to enhancing recall of persons whom might otherwise be forgotten in network elicitation interviews (Brewer, 2000) may lie in using recall cues and strategies that focus on the social connections between persons. In two randomized controlled experiments, Brewer and colleagues (2001, 2005) evaluated the effectiveness of different cues in eliciting additional sexual and drug injection partners after interviewees had finished recalling them on their own. One interview strategy they tested was inspired by Brewer et al.'s (2002b) observations of clustering by social proximity. This strategy involves reading back to the interviewee the names of the partners the interviewee freely recalled. For each partner, the interviewer asks the interviewee to think of other persons who know, hang out, or interact with that partner and list any of these persons if she or he had sex/injected drugs with them during the recall period but forgot to mention earlier. The results showed that this technique was reasonably effective in eliciting additional injection partners but was only slightly effective in eliciting additional sexual partners. More research is required to determine whether similar techniques enhance recall for other social relations.
References
Bond, C. F., Jr., & Brockett, D. R. (1987). A social context-personality index theory of memory for acquaintances. Journal of Personality and Social Psychology 52, 1110-1121.
Bond, C. F., Jr., Jones, R. L., & Weintraub, D. L. (1985). On the unconstrained recall of acquaintances: A sampling-traversal model. Journal of Personality and Social Psychology 49, 327-337.
Boster, J. S. (1987). Agreement between biological classification systems is not dependent on cultural transmission. American Anthropologist 89, 914-919.
Brewer,
Brewer,
Brewer,
Brewer,
Brewer,
Brewer,
Brewer,
Brewer, D. D., Potterat, J. J., Muth, S. Q., Malone, P. Z., Montoya, P. A., Green, D. A., Rogers, H. L., & Cox, P. A. (2005). Randomized trial of supplementary interviewing techniques to enhance recall of sexual partners in contact interviews. Sexually Transmitted Diseases 32, 189-193.
Brewer,
Daly, M., &
Dunbar, R. I. M. (1993). Coevolution of neocortical size, group size and language in humans. Behavioral and Brain Sciences 16, 681-735.
Fiske, A. P. (1995). Social schemata for remembering people: Relationships and person attributes in free recall of acquaintances. Journal of Quantitative Anthropology 5, 305-324.
Freeman, L. C., Freeman, S. C., & Michaelson, A. G. (1988). On human social intelligence. Journal of Social and Biological Structures 11, 415-425.
Lawler, E. L., Lenstra, J. K., Rinnooy Kan, A. H. G., &
Shmoys, D. B. (Eds.). (1985). The
Traveling Salesman Problem.
Mogoutov, A., & Vichnevskaia, T. (1995). Ego-centered
network in migration. Paper presented at the International Social Network
Conference,
Padberg, M., & Rinaldi, G. (1991). A branch-and-cut
algorithm for the resolution of large-scale symmetric traveling salesman
problems.
Roenker, D. L., Thompson, C. P., & Brown, S. C. (1971). Comparisons of measures for the estimation of clustering in free recall. Psychological Bulletin 76, 45-48.
Romney, A. K., Brewer,
Rosenthal, R. (1991). Meta-analytic
Procedures for Social Research.
Puff, C. R. (Ed.). (1979). Memory
Organization and Structure.
Valente, T. W., & Vlahov, D. (2001). Selective risk taking among needle exchange participants: Implications for supplemental interventions. American Journal of Public Health 91, 406-411.
Webster, C. M. (1993/1994). Data type: A comparison of observational and cognitive measures. Journal of Quantitative Anthropology 4, 313-328.
Weller, S. C., & Romney, A. K. (1988). Systematic Data Collection.
Williams, M. D., & Hollan, J. D. (1981). The process of retrieval from very long-term memory. Cognitive Science 5, 87-119.
Appendix A
This appendix illustrates how the ARC and control ARC are calculated with the recalls of two subjects from study 1. In these examples, clustering scores are expressed in terms of proximities rather than distances. Subject #7 recalled 31 persons and subject #13 recalled 23 persons. The lower half matrices for the social proximities among the persons they recalled appear on the following two pages. The order of the rows and columns in each matrix corresponds to the order in which persons were recalled. For subject #7, the observed (o), expected (e), and maximum (m) possible social proximity clustering scores are 7.59, 4.15, and 13.23, respectively, resulting in an ARC of .38 ((7.59 - 4.15) / (13.23 - 4.15)). For subject #13, the observed, expected, and maximum possible social proximity clustering scores are 6.21, 4.53, and 10.64, respectively, resulting in an ARC of .28 ((6.21 - 4.53) / (10.64 - 4.53)). The generally higher social proximity values on the diagonal (cells for row person i and column person i - 1, the sum of which equals o) compared with the lower off-diagonal values give a rough visual indication of the clustering by social proximity. Graphic representations in Brewer and Yang (1994), Brewer (1995a), and Brewer, Garrett, and Rinaldi (2002) also display the clustering by social proximity.
Subject #7's recall sequence, in terms of each recalled person's sex (F = female, M = male), is: M, F, M, M, M, F, F, M, F, F, F, F, F, F, F, F, M, M, F, F, M, M, M, M, M, M, M, F, F, F, and F. The observed, expected, and observed scores for clustering by sex are 21, 14.65, and 29 for this subject, yielding an ARC of .44 ((21 - 14.65) / (29 - 14.65)). Subject #13's recall sequence, in terms of each recall person's sex, is: M, F, M, M, F, F, M, M, M, F, F, F, F, M, F, F, M, M, F, M, M, M, and F. The observed expected, and observed scores for clustering by sex are 11, 10.52, and 21 for this subject, yielding an ARC of .05 ((11 - 10.52) / (21 - 10.52)).
Social
proximities among recalled persons for subject #7, study 1
.36 .36 1.00 .27 .18 .18 .27 .18 .18 .27 .27 .18 .18 .27 .18 .27 .18 .18 .18 .18 .55 .27 .27 .27 .27 .55 .18 .18 .00 .00 .00 .00 .20 .20 .00 .20 .00 .44 .44 .00 .00 .00 .00 .11 .00 .27 .18 .18 .18 .18 .55 .45 .18 .20 .00 .18 .18 .18 .27 .18 .36 .36 .18 .00 .00 .45 .09 .09 .09 .18 .18 .09 .09 .18 .00 .00 .18 .09 .09 .09 .09 .09 .09 .09 .09 .09 .00 .00 .09 .09 .09 .09 .09 .09 .09 .09 .09 .09 .09 .00 .00 .09 .09 .09 1.00 .00 .00 .00 .00 .00 .00 .00 .00 .00 .00 .00 .00 .00 .00 .00 .27 .18 .18 .27 .36 .18 .18 .36 .00 .00 .18 .18 .09 .09 .09 .00 .00 .00 .00 .00 .00 .00 .00 .00 .00 .00 .00 .00 .00 .00 .00 .00 .00 .33 .22 .22 .22 .22 .33 .22 .33 .00 .00 .33 .33 .11 .11 .11 .00 .22 .00 .27 .18 .18 .27 .18 .73 .45 .18 .20 .00 .55 .36 .09 .09 .09 .00 .18 .00 .44 .00 .00 .00 .00 .00 .13 .00 .00 .20 .00 .13 .00 .00 .00 .00 .00 .00 .00 .00 .13 .00 .00 .00 .00 .00 .09 .00 .00 .20 .00 .09 .09 .00 .00 .00 .00 .00 .00 .00 .09 1.00 .00 .00 .00 .00 .09 .00 .00 .00 .00 .00 .00 .00 .00 .45 .45 .00 .00 .00 .00 .00 .00 .00 .09 .09 .09 .18 .09 .09 .09 .09 .00 .00 .27 .09 .82 .09 .09 .00 .09 .00 .11 .09 .00 .00 .00 .18 .36 .36 .09 .09 .09 .09 .18 .00 .22 .09 .09 .00 .00 .00 .00 .09 .00 .22 .18 .00 .00 .00 .00 .36 .18 .18 .36 .18 .64 .36 .18 .20 .00 .36 .18 .09 .09 .09 .00 .18 .00 .33 .82 .13 .09 .00 .09 .18 .18 .09 .09 .09 .09 .36 .18 .09 .00 .00 .27 .18 .09 .09 .09 .00 .09 .00 .22 .27 .00 .09 .00 .09 .00 .18 .45 .18 .18 .18 .18 .36 .36 .18 .00 .00 .55 .36 .18 .09 .09 .00 .18 .00 .56 .55 .00 .00 .00 .18 .18 .36 .27 .36 .18 .18 .27 .27 .27 .27 .27 .00 .00 .36 .27 .55 .09 .09 .00 .18 .00 .33 .18 .00 .00 .00 .36 .09 .27 .09 .36 .27 .27 .27 .18 .18 .36 .55 .27 .00 .11 .36 .27 .18 .09 .09 .00 .18 .00 .22 .27 .00 .00 .00 .18 .18 .36 .09 .18 .36 .09 .09 .09 .09 .09 .18 .18 .09 .00 .00 .27 .27 .00 .00 .00 .00 .09 .00 .22 .27 .00 .00 .00 .00 .09 .09 .09 .27 .09 .09
Social proximities among recalled persons for subject #13, study 1
.27 .27 1.00 .18 .36 .36 .18 .18 .18 .09 .33 .22 .22 .22 .22 .27 .27 .27 .27 .18 .44 .00 .00 .00 .00 .00 .00 .09 .00 .00 .00 .00 .00 .00 .00 .36 .27 .27 .27 .18 .55 .22 .27 .00 .00 .27 .18 .18 .09 .27 .33 .18 .00 .00 .36 .27 .27 .27 .18 .55 .22 .27 .00 .00 1.00 .36 .18 .18 .18 .18 .36 .56 .36 .00 .00 .18 .36 .18 .09 .09 .09 .36 .09 .11 .18 .09 .00 .09 .09 .09 .09 .18 .18 .18 .09 .36 .33 .27 .09 .09 .27 .27 .27 .36 .09 .18 .18 .18 .09 .45 .33 .27 .09 .00 .36 .36 .36 .55 .09 .45 .18 .18 .18 .18 .36 .33 .27 .09 .00 .36 .27 .36 .36 .09 .18 .36 .09 .09 .09 .00 .18 .22 .27 .09 .00 .09 .09 .09 .27 .09 .18 .27 .18 .18 .18 .18 .09 .55 .33 .27 .09 .00 .36 .27 .36 .36 .09 .36 .55 .64 .36 .27 .36 .36 .18 .27 .33 .18 .00 .00 .27 .36 .27 .45 .09 .18 .27 .36 .18 .27 .55 .18 .18 .09 .18 .22 .18 .00 .00 .18 .27 .18 .18 .09 .18 .18 .18 .09 .18 .27 .27 .18 .18 .09 .18 .22 .18 .00 .00 .18 .27 .18 .18 .09 .27 .18 .36 .09 .27 .27 .27 .09 .18 .18 .82 .09 .22 .18 .00 .00 .09 .09 .09 .18 .55 .09 .09 .18 .00 .09 .09 .09 .09
The tables below show the observed, expected, and maximum possible social proximity clustering scores within each of the sex clusters (of size 3 or larger, in serial order) recalled by each of these sample subjects. The social proximities of the persons in each cluster are bolded in the previous lower half matrices for these subjects.
Observed,
expected, and maximum possible social proximity clustering scores within sex
clusters, subject #7, study 1
|
Cluster |
Observed |
Expected |
Maximum |
|
1 |
0.45 |
0.42 |
0.45 |
|
2 |
1.64 |
0.76 |
1.73 |
|
3 |
1.36 |
0.53 |
1.49 |
|
4 |
0.82 |
0.68 |
1 |
|
Sum |
4.27 |
2.39 |
4.67 |
Observed,
expected, and maximum possible social proximity clustering scores within sex
clusters, subject #13, study 1
|
Cluster |
Observed |
Expected |
Maximum |
|
1 |
0.45 |
0.30 |
0.45 |
|
2 |
0.91 |
1.23 |
1.73 |
|
3 |
0.55 |
0.55 |
0.55 |
|
Sum |
1.91 |
2.08 |
2.73 |
The resulting social proximity ARCs within sex clusters, based on the summed observed, expected, and maximum scores, are 0.83 and -0.26 for subjects #7 and #13, respectively. Although subject #13 displayed less clustering by social proximity within sex clusters than expected, these clusters were small, and this subject displayed essentially no clustering by sex.
Appendix B
The following paragraphs are descriptions of the four relational models provided by Alan Page Fiske. Subjects in study 5 used these descriptions to classify their relationships with the persons they recalled.
Communal Sharing: You and this person take a 'one for all and all for one' approach toward one another. You each feel that 'what's mine is yours' and that what happens to the other person is nearly as important as what happens to you. If the other person needed your help, you would try to cancel your plans and help them out, and they would do the same for you. Similarly, you would give the person the shirt off your back if they really needed it and they would do the same for you. You willingly share food with this person and, if necessary, you would happily share a soda using the same straw or share a meal using the same fork.
Authority Ranking: One of you tends to 'call the shots' and take the initiative in this relationship and the other tends to follow along. One of you makes most of the decisions and the other one goes along with that person's choices. The one in charge usually gets their way, and takes responsibility for things. The other person is a follower in this relationship and backs the other person up, knowing that they can depend on the one in charge to lead and protect them when it's needed.
Equality Matching: Your relationship is structured on a 50:50 basis. You feel like you and the other person are pretty equal in the things you do for each other. If they do something for you, you will try to do the same thing in return for them sometime. If the two of you were dividing something, you'd probably split it down the middle into even shares. You often take turns doing things. As a way of keeping things balanced, you more or less keep track of favors and obligations between you. And you get irritated when you feel that the other person is taking more than they are giving. What you each want is equal treatment and equal shares.
Market Pricing: You interact with this person in a purely rational, businesslike way, because you 'get your money's worth.' Each of you feels entitled to a fair rate of return, in proportion to what you put into the interaction. How much you get out of your dealings with this person depends on precisely how much you put in. So you each keep track of the ratio of your 'cost' (in terms of money, time, effort, or aggravation) in relation to your 'benefits.' The interaction basically comes down to practical matters like these. When it comes down to it, you each choose to participate when it is profitable in terms of what you have to invest and the rewards that you get out of it.